Information extraction (IE) is a pivotal area of artificial intelligence that transforms unstructured text into structured, actionable data. Despite their expansive capacities, traditional large language models (LLMs) often fail to comprehend and execute the nuanced directives required for precise IE. These challenges primarily manifest in closed IE tasks, where a model must adhere to stringent, pre-defined schemas.
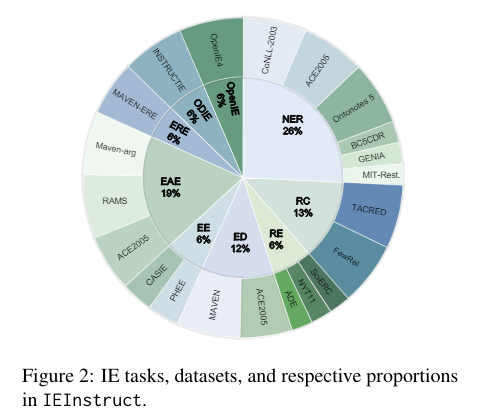
IE tasks compel models to discern and categorize text in formats that align with predefined structures, such as named entity recognition and relation classification. However, existing LLMs typically falter when tasked with the nuanced understanding and alignment necessary for effective IE. Researchers have traditionally employed strategies such as prompt engineering, which involves providing detailed annotations and guidelines to assist LLMs without altering underlying model parameters.
The research community has observed a critical need for a methodology that enhances LLMs’ understanding of structured tasks and improves execution accuracy. In response, researchers from Tsinghua University have introduced a new approach called ADELIE (Aligning large language moDELs on Information Extraction). This approach leverages a specialized dataset, IEInstruct, comprising over 83,000 instances across various IE formats, including triplets, natural language responses, and JSON outputs.

ADELIE diverges from conventional methods by integrating supervised fine-tuning with an innovative Direct Preference Optimization (DPO) strategy. This blend enables the model to align more closely with the intricacies of human-like IE processing. Initial training involves a mix of IE-specific and generic data, using the LLAMA 2 model over 6,306 gradient steps, which ensures the retention of broad linguistic capabilities alongside specialized IE performance.
Performance metrics reveal that ADELIE models, ADELIESFT and ADELIEDPO, achieve benchmark-setting results. In evaluations against held-out datasets, ADELIESFT shows an average F1 score improvement of 5% over standard LLM outputs in closed IE tasks. The improvements are even more pronounced for open IE, with ADELIE models outperforming state-of-the-art alternatives by 3-4% margins in robustness and extraction accuracy. In the realm of on-demand IE, the models demonstrate a nuanced understanding of user instructions, translating into highly accurate data structuring.
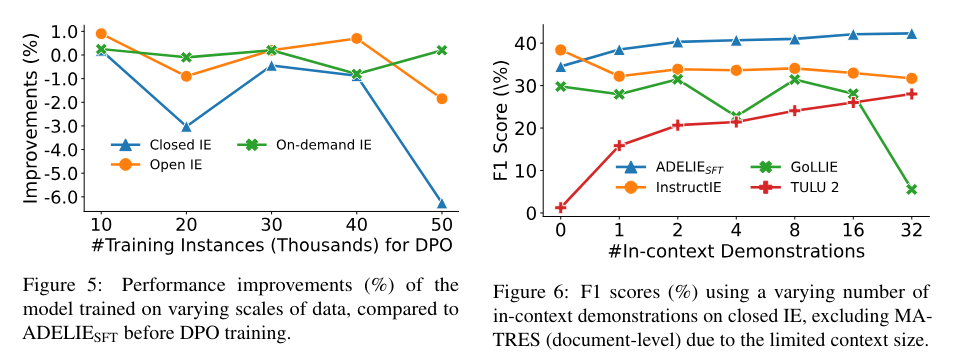
In conclusion, ADELIE’s methodical training and optimization translate into a potent alignment of LLMs with IE tasks, demonstrating that a focused approach to data diversity and instruction specificity can bridge the gap between human expectations and machine performance. This alignment does not compromise the models’ general capabilities, which is often a concern with task-specific tuning. The impressive results across various metrics and task types underscore the potential of ADELIE to set new standards in information extraction, making it a valuable tool for multiple applications, from academic research to real-world data processing.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
