Research on scaling laws for LLMs explores the relationship between model size, training time, and performance. While established principles suggest optimal training resources for a given model size, recent studies challenge these notions by showing that smaller models with more computational resources can outperform larger ones. Despite understanding emergent behaviors in large models, there needs to be more quantitative analysis on how model size affects its capacity post-sufficient training. Traditional theories propose that increasing model size improves memorization, generalization, and fitting complex functions, but practical outcomes often deviate due to overlooked factors.
Researchers from Meta/FAIR Labs and Mohamed bin Zayed University of AI have devised a systematic framework to investigate the precise scaling laws governing the relationship between the size of LMs and their capacity to store knowledge. While it’s commonly assumed that larger models can hold more knowledge, the study aims to determine whether the total knowledge scales linearly with model size and what constant defines this scaling. Understanding this constant is pivotal for evaluating the efficiency of transformer models in knowledge storage and how various factors like architecture, quantization, and training duration impact this capacity. They train language models of varying sizes by defining knowledge as (name, attribute, value) tuples and generating synthetic datasets. They evaluate their knowledge storage efficiency by comparing trainable parameters to the minimum bits required to encode the knowledge.
Language models store factual knowledge as tuples, each consisting of three strings: (name, attribute, and value). The study estimates the number of knowledge bits a language model can store, with findings indicating that models can store 2 bits of knowledge per parameter. Training duration, model architecture, quantization, sparsity constraints, and data signal-to-noise ratio impact a model’s knowledge storage capacity. Prepending training data with domain names like wikipedia.org significantly increases a model’s knowledge capacity by allowing models to identify and prioritize domains rich in knowledge.
In the investigation, the researchers focus on factual knowledge represented as tuples, such as (USA, capital, Washington D.C.), and establish that language models can store approximately 2 bits of knowledge per parameter, even with quantization to int8. Moreover, they find that appending domain names to training data significantly enhances a model’s knowledge capacity, enabling language models to identify and prioritize domains rich in knowledge autonomously. Through controlled experiments, they elucidate how factors like training duration, architecture, quantization, sparsity constraints, and data signal-to-noise ratio affect a model’s knowledge storage capacity, offering valuable insights for developing and optimizing language models.
The study outlines key findings on language model capacity:
- GPT2 consistently achieves a 2-bit per parameter capacity ratio across diverse data settings, implying a 7B model could exceed the knowledge in English Wikipedia.
- Longer training time, with 1000 exposures per knowledge piece, is crucial for maintaining this ratio.
- Model architecture influences capacity, with GPT2 outperforming LLaMA/Mistral due to gated MLP.
- Quantization to int8 maintains capacity, while int4 reduces it.
- Mixture-of-experts models slightly decrease capacity but remain efficient.
- Junk data significantly reduces model capacity, but prepending useful data mitigates this effect. This systematic approach offers precise comparisons of models and insights into critical aspects like training time, architecture, quantization, and data quality.
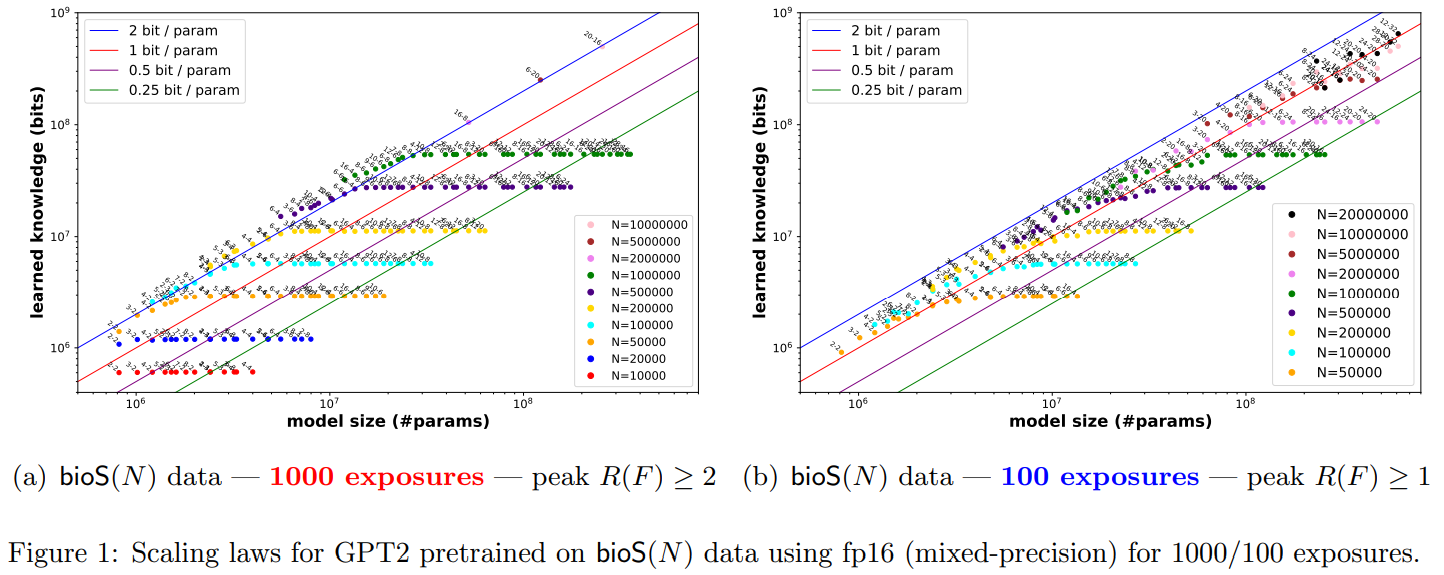
In conclusion, researchers discovered a consistent pattern in investigating language model scaling laws: a fully-trained transformer model can effectively store 2 bits of knowledge per parameter, regardless of its size or other factors, such as quantization to int8. They explored the impact of various hyperparameters on these scaling laws, including training duration, model architectures, precision, and data quality. The methodology offers a rigorous framework for comparing model capabilities, aiding practitioners in decision-making regarding model selection and training. Moreover, the research lays the groundwork for addressing the fundamental question of optimal language model size, potentially informing future advancements toward achieving Artificial General Intelligence (AGI).
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Want to get in front of 1.5 Million AI Audience? Work with us here
Sana Hassan, a consulting intern at Marktechpost and dual-degree student at IIT Madras, is passionate about applying technology and AI to address real-world challenges. With a keen interest in solving practical problems, he brings a fresh perspective to the intersection of AI and real-life solutions.
