As Artificial Intelligence (AI) systems advance, a fascinating trend has emerged: their representations of data across different architectures, training objectives, and even modalities seem to be converging. Researchers have put forth, as shown in Figure 1, a thought-provoking hypothesis to explain this phenomenon called the “Platonic Representation Hypothesis.” At its core, this hypothesis posits that various AI models strive to capture a unified representation of the underlying reality that generates the observable data.
Historically, AI systems were designed to tackle specific tasks, such as sentiment analysis, parsing, or dialogue generation, each requiring a specialized solution. However, modern large language models (LLMs) have demonstrated remarkable versatility, competently handling multiple language processing tasks using a single set of weights. This trend extends beyond language processing, with unified systems emerging across data modalities, combining architectures for the simultaneous processing of images and text.
The researchers behind the Platonic Representation Hypothesis argue that representations in deep neural networks, particularly those used in AI models, are converging toward a common representation of reality. This convergence is evident across different model architectures, training objectives, and data modalities. The central idea is that there exists an ideal reality that underlies our observations, and various models are striving to capture a statistical representation of this reality through their learned representations.
Several studies have demonstrated the validity of this hypothesis. Techniques like model stitching, where layers from different models are combined, have shown that representations learned by models trained on distinct datasets can be aligned and interchanged, indicating a shared representation. Moreover, this convergence extends across modalities, with recent language-vision models achieving state-of-the-art performance by stitching pre-trained language and vision models together.
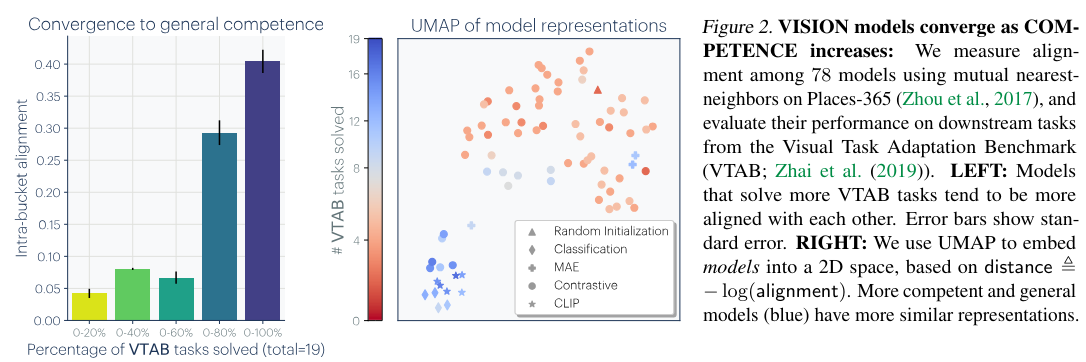
Researchers have also observed that as models become larger and more competent across tasks, their representations become more aligned (Figure 2). This alignment extends beyond individual models, with language models trained solely on text exhibiting visual knowledge and aligning with vision models up to a linear transformation.
The researchers attribute several factors to the observed convergence in representations:
1. Task Generality: As models are trained on more tasks and data, the volume of representations that satisfy these constraints becomes smaller, leading to convergence.
2. Model Capacity: Larger models with increased capacity are better equipped to approximate the globally optimal representation, driving convergence across different architectures.
3. Simplicity Bias: Deep neural networks exhibit an inherent bias towards finding simple solutions that fit the data, favoring convergence towards a shared, simple representation as model capacity increases.
The central hypothesis posits that the representations are converging toward a statistical model of the underlying reality that generates our observations. This representation will be useful for a wide range of tasks grounded in reality and relatively simple, aligning with the notion that the fundamental laws of nature are indeed simple functions.
The researchers formalize this concept by considering an idealized world consisting of a sequence of discrete events sampled from an unknown distribution. They demonstrate that certain contrastive learners can recover a representation whose kernel corresponds to the pointwise mutual information function over these underlying events, suggesting convergence toward a statistical model of reality.
The Platonic Representation Hypothesis has several intriguing implications. Scaling models in terms of parameters and data could lead to more accurate representations of reality, potentially reducing hallucination and bias. Additionally, it implies that training data from different modalities could be shared to improve representations across domains.
However, the hypothesis also faces limitations. Different modalities may contain unique information that cannot be fully captured by a shared representation. Furthermore, the convergence observed so far is primarily limited to vision and language, with other domains like robotics exhibiting less standardization in representing world states.
In conclusion, the Platonic Representation Hypothesis presents a compelling narrative about the trajectory of AI systems. As models continue to scale and incorporate more diverse data, their representations may converge toward a unified statistical model of the underlying reality that generates our observations. While this hypothesis faces challenges and limitations, it offers valuable insights into the pursuit of artificial general intelligence and the quest to develop AI systems that can effectively reason about and interact with the world around us.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 42k+ ML SubReddit
Vineet Kumar is a consulting intern at MarktechPost. He is currently pursuing his BS from the Indian Institute of Technology(IIT), Kanpur. He is a Machine Learning enthusiast. He is passionate about research and the latest advancements in Deep Learning, Computer Vision, and related fields.
