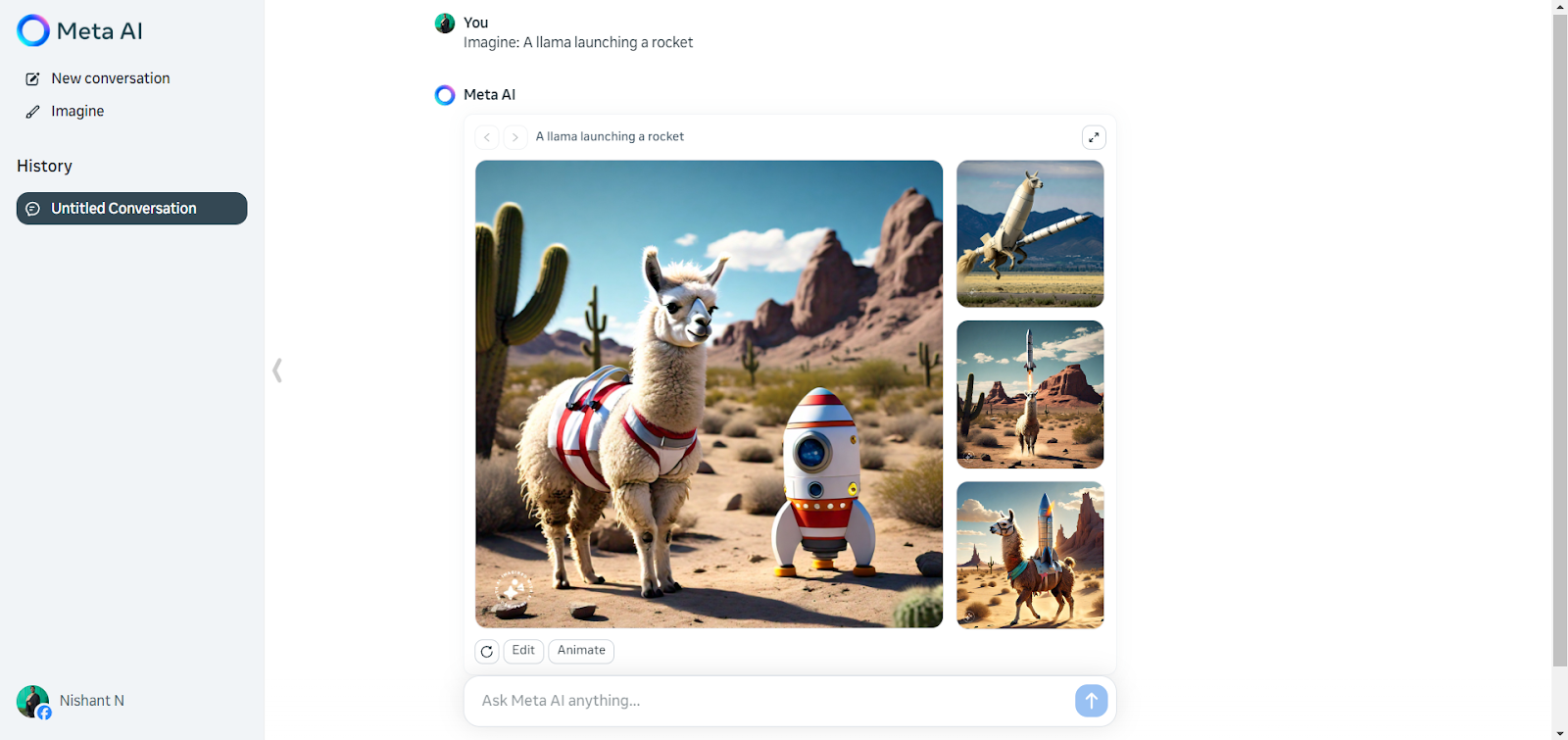
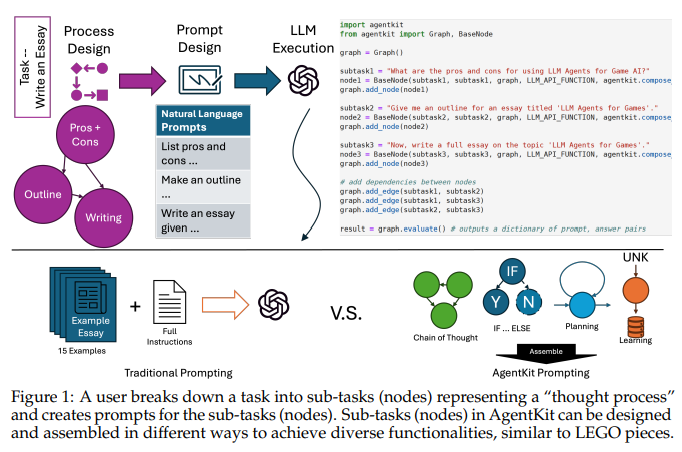
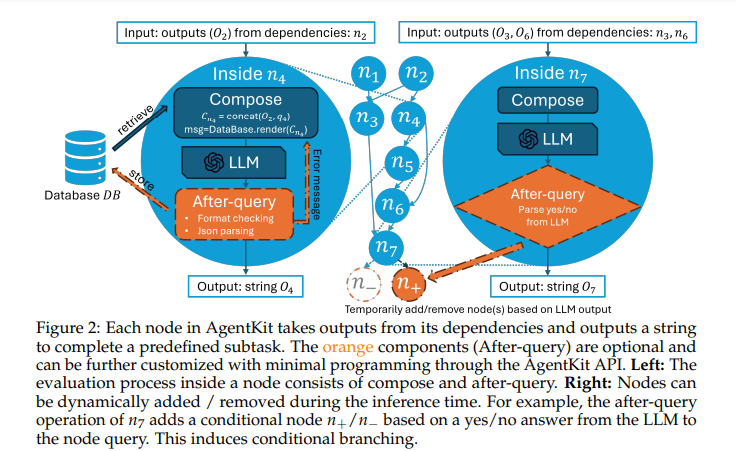
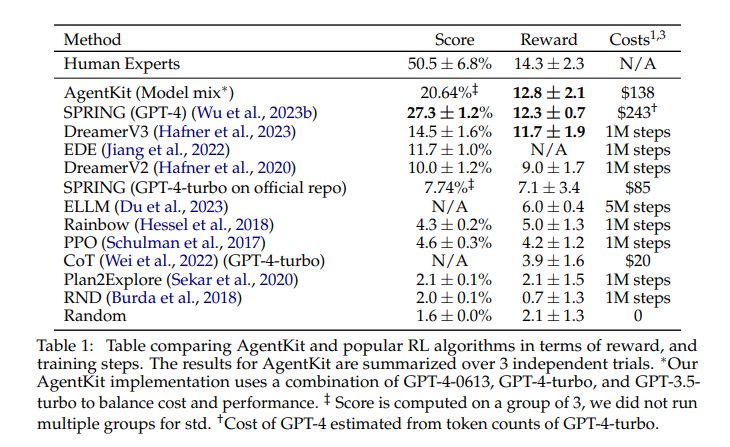
Job Title: Chief Information Security Officer (CISO)
Department: Information Technology
Position reports to: Chief Information Officer
Positions that report to this position:
DOL Classification: Exempt
Job Purpose:
The CISO is the primary point-of-contact for information security and will brief CIO and other executives regularly on current cybersecurity threats and challenges, and the status of the information security management systems aiming to improve information security continuously and measurably across the organization. The CISO implements, oversees, and audits cybersecurity identification, protection, detection, response, and recovery processes and systems, with emphasis on IT Security and Compliance.
Job Responsibilities:
Security Strategy Development & Implementation:
- Working knowledge of system development life cycle in software development, source code development, hardware integration, software virtualization, system administrator, network infrastructure implementation, and database administration. Experience with internal and cloud based hosting and technology delivery models.
- Develops, implements, and monitors a strategic, comprehensive enterprise information security and IT risk management program to ensure the integrity, confidentiality, and availability of information assets.
- Applies a broad range of advanced expertise of technology and security principles, best practices, policies and procedures to guide other technology staff in the completion of difficult and complex assignments crossing multiple functional areas.
- Directs and oversees business continuity planning, disaster recovery; exercising each plan, updating, and modifying with each business partner to ensure positive outcomes.
- Develops and implements information security policies, standards, guidelines, and procedures.
- Works collaboratively with technology management peers to ensure security is appropriately included in all development and maintenance activities, including automated security testing where appropriate
- Regularly update the executive team and the board of directors on the status of information security, risks, and projects.
Cybersecurity management:
- Working with the cyber security and development team members, evaluates new cybersecurity threats and IT systems for vulnerabilities and malicious activities and to identify potential controls to mitigate them
- Helps determine the vulnerabilities, risks, impacts and remediation approaches on web development and other software tool and systems.
- Stays current with the cybersecurity threats and adapts current processes and technologies to mitigate risks to the organization
- Investigates any breaches and other security incidents that occur
Risk Management:
- Performs regular security assessments, audits, and relevant risk assessments, communicating results to executive management and board members. These activities will be done internally as well as through third parties.
- Leads the incident response team in effectively mitigating security incidents, including data breaches and cyber-attacks, and collaborate with the legal department for any necessary follow-up.
- Ensures that the company is in compliance with all relevant legal and regulatory requirements, including data protection laws and cybersecurity standards and any industry-specific guidelines.
- Develops and manages a security awareness and training program for all associates.
- Ensures that IT security is integrated into the third-party vendor risk management process.
Qualifications:
Education and Experience: Bachelor’s degree in MIS, CS or equivalent work experience plus 10+ years of progressively more responsibility in cyber security leadership roles. Strong technical background with knowledge of web development, various software tools, hosting models, hardware platforms and third party technology vendors.
Skills and Knowledge: Project management, attention to detail, problem solving, customer service, critical thinking, above average verbal and written communication skills, ability to explain complex concepts in simple and understandable terms, and collaboration, ability to work independently or work effectively through others, public speaking, and rapport building.
Essential Functions:
This person must be able to understand and analyze complex business processes. They must be able to communicate verbally with tact and diplomacy and think on their feet. They must be able to learn new technology and grasp business concepts quickly in order to synthesize solutions. This person must be able to make decisions under pressure, problem-solve and troubleshoot complex technology systems
Physical Demands:
The physical demands described here are representative of those that must be met by an associate to successfully perform the essential functions of the job. Reasonable accommodations may be made to enable individual with disabilities to perform the essential functions.
The associate may travel up to 10% of the time by air or car to other office or business locations.
Working Conditions:
The work environment characteristics described here are representative of those an associate encounters while performing the essential functions of this job. Reasonable accommodations may be made to enable individuals with disabilities to perform the essential functions.
While performing the duties of this job, the associate is exposed to normal office working conditions that are climate controlled. The associate would not be exposed to extreme heat or cold or other workplace hazards. The noise level in the work environment is usually low.
This job description is not intended to be an exhaustive list of skills, efforts, duties, responsibilities or working conditions associated with this position. The CISO assumes other responsibilities as assigned by the Chief Information Officer.