Artificial intelligence and machine learning are fields focused on creating algorithms to enable machines to understand data, make decisions, and solve problems. Researchers in this domain seek to design models that can process vast amounts of information efficiently and accurately, a crucial aspect in advancing automation and predictive analysis. This focus on the efficiency and precision of AI systems remains a central challenge, particularly as the complexity and size of datasets continue to grow.
AI researchers encounter significant progress in improving mixing models for high performance without compromising accuracy. With data sets expanding in size and complexity, the computational cost associated with training and running these models is a critical concern. The goal is to create models that can efficiently handle these large datasets, maintaining accuracy while operating within reasonable computational limits.
Existing work includes techniques like stochastic gradient descent (SGD), a cornerstone optimization method, and the Adam optimizer, which enhances convergence speed. Neural architecture search (NAS) frameworks enable the automated design of efficient neural network architectures, while model compression techniques like pruning and quantization reduce computational demands. Ensemble methods, combining multiple models’ predictions, enhance accuracy despite higher computational costs, reflecting the ongoing effort to improve AI systems.
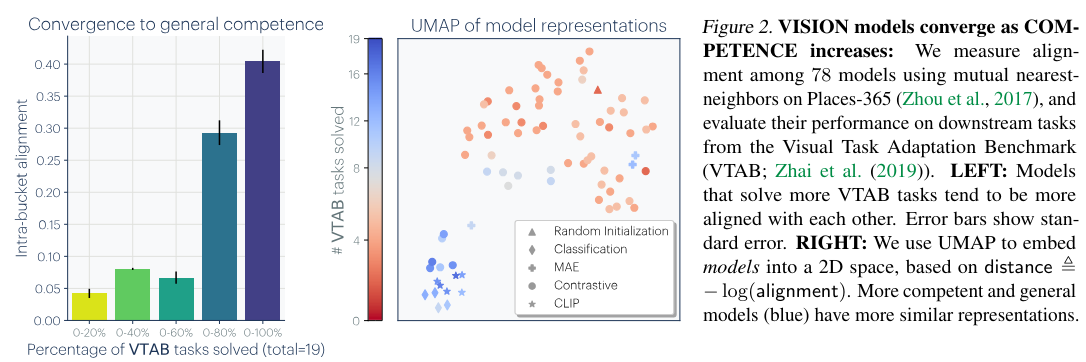
Researchers from the University of California, Berkeley, have proposed a new optimization method to improve computational efficiency in machine learning models. This method is unique due to its heuristic-based approach, which strategically navigates the optimization process to identify optimal configurations. By combining mathematical techniques with heuristic methods, the research team created a framework that reduces computation time while maintaining predictive accuracy, thus making it a promising solution for handling large datasets.
The methodology utilizes a detailed algorithmic design guided by heuristic techniques to optimize the model parameters effectively. The researchers validated the approach using ImageNet and CIFAR-10 datasets, testing models like U-Net and ConvNet. The algorithm intelligently navigates the solution space, identifying optimal configurations that balance computational efficiency and accuracy. By refining the process, they achieved a significant reduction in training time, demonstrating the potential of this method to be used in practical applications requiring efficient handling of large datasets.
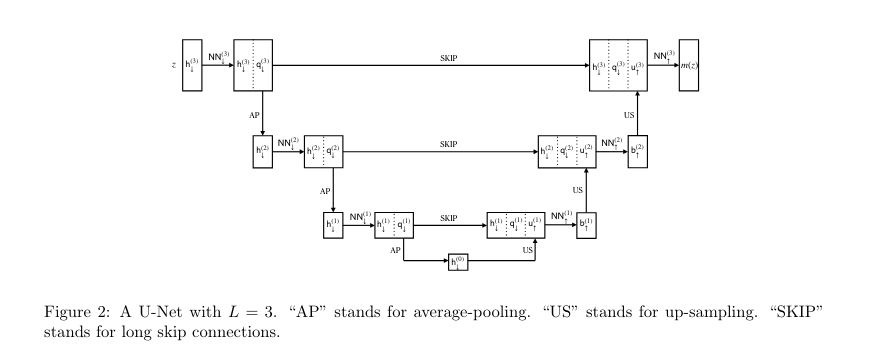
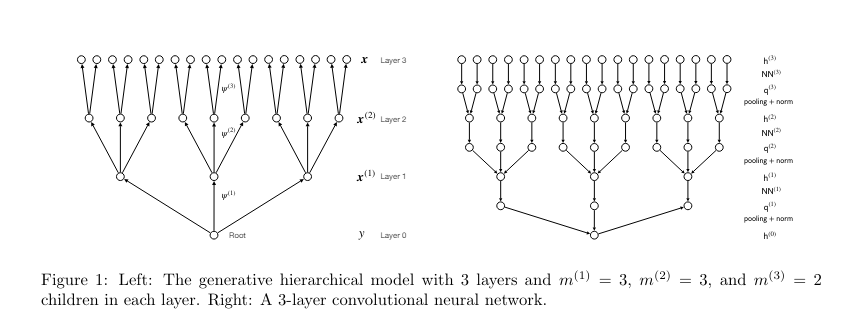
The researchers presented theoretical insights into how U-Net architectures can be used effectively within generative hierarchical models. They demonstrated that U-Nets can approximate belief propagation denoising algorithms and achieve an efficient sample complexity bound for learning denoising functions. The paper provides a theoretical framework showing how their approach offers significant advantages for managing large datasets. This theoretical foundation opens avenues for practical applications in which U-Nets can significantly optimize model performance in computationally demanding tasks.
To conclude, the research contributes significantly to artificial intelligence by introducing a novel optimization method for efficiently refining model parameters. The study emphasizes the theoretical strengths of U-Net architectures in generative hierarchical models, specifically focusing on their computational efficiency and ability to approximate belief propagation algorithms. The methodology presents a unique approach to managing large datasets, highlighting its potential application in optimizing machine learning models for practical use in diverse domains.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.