GovAI blog posts represent the views of their authors, rather than the views of the organisation.
Summary
The UK AI Safety Summit was largely a success. To build on it, the international community has committed to hold further AI Safety Summits. The first follow-on summit will be held in mid-2024, with the Republic of Korea serving as host.
One underlying goal, for the organisers of the next summit, should be to reinforce the world’s commitment to an ambitious summit series. Even participants who are committed to further summits will need to decide, in future years, just how ambitious or pro forma their participation will be. The next summit is an opportunity to ensure ambitious participation, by demonstrating the promise of the series.
To this end, three concrete goals for the Korean summit could be to:
Create shared clarity on the need for progress in AI safety, for instance by:
- Disseminating preliminary findings from the International Scientific Report on Advanced AI Safety on emerging risks (previously called the “State of the Science” report)
- Holding discussions on the limits of current technologies, practices, and governance regimes for managing these risks (i.e. on “preparedness gaps”)
Showcase progress since the last summit, for instance by:
- Inviting research institutes (e.g. the UK AI Safety Institute) to share new findings
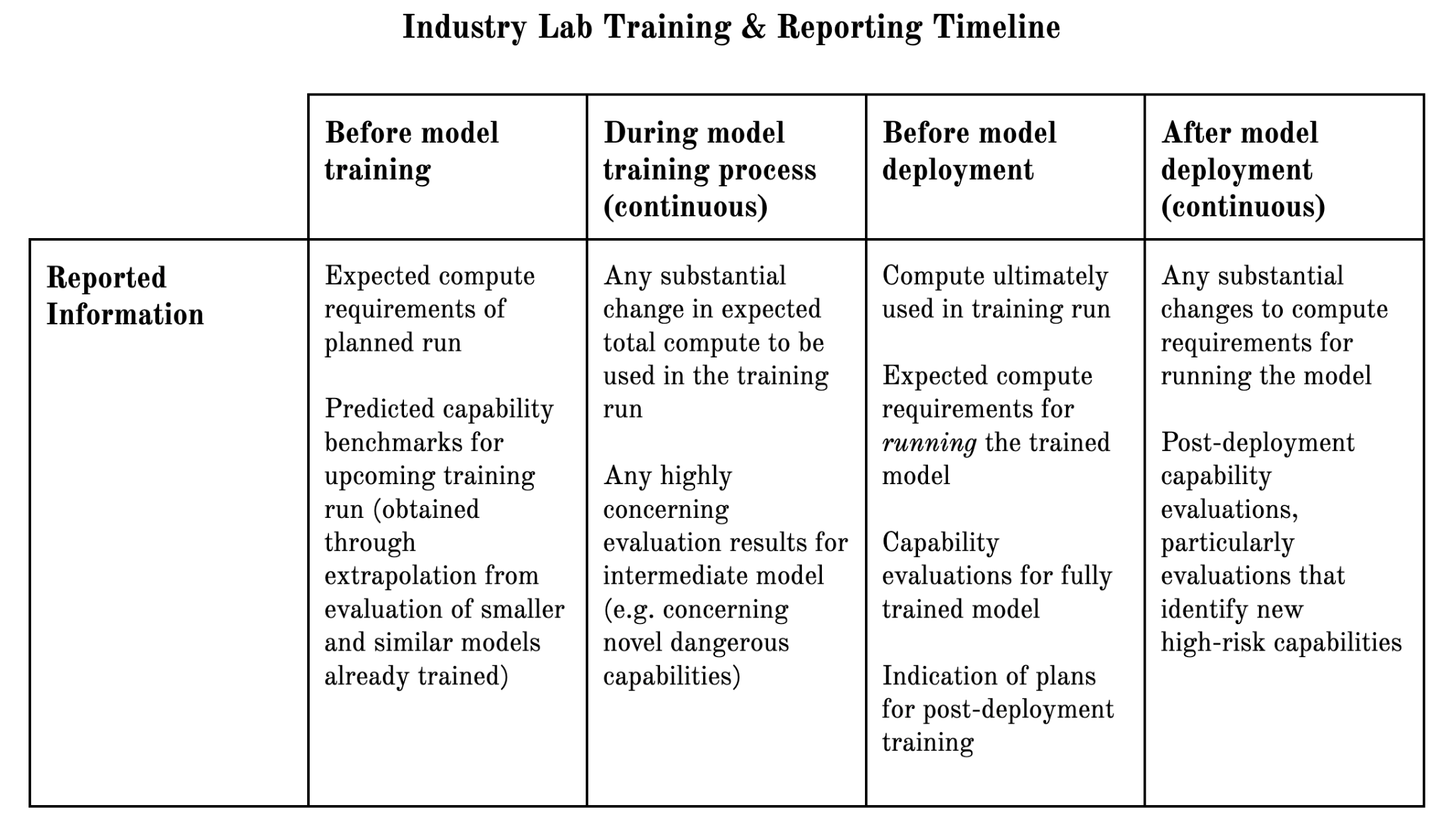
- Inviting AI companies to share updated reports on their safety practices and safety commitments
- Inviting governments to give progress reports on their domestic safety initiatives
Begin to build a long-term vision and roadmap for the series, for instance by:
- Producing a more detailed statement on the objectives of the series
- Identifying forward processes to make progress on these objectives
- Having companies commit to sharing updated AI safety policies at future summits and commit to adhering to their policies
- Launching a working group to investigate the need for new international institutions
Accomplishing these goals would be challenging, but would make the promise of the series clearer and lay a strong foundation for future summits. Participants would leave with a firmer sense of the problems the series is addressing, greater confidence that progress on these problems is possible, and a vision for how future summits will ultimately bring the world closer to shared solutions.
Ensuring an ambitious summit series
The first AI Safety Summit generated significant momentum. Remarkable outcomes included twenty-nine governments — including the US, EU, and China — signing a joint declaration on risks and opportunities from AI, seven leading AI companies releasing public reports on their own safety practices, and the UK government launching an AI Safety Institute.
However, there is no guarantee that this momentum will be sustained. It is common for international forums to become less productive over time. If participants lose clarity on a forum’s purpose or lose faith that the forum can achieve its purpose, then their participation will tend to become increasingly pro forma.
When future AI Safety Summits are held, both governments and companies will need to decide how ambitiously to participate. For example, governments will need to decide whether to send their most senior representatives, whether to dedicate substantial energy to pre-summit negotiations, and whether to sign onto bold shared commitments. If they do not participate ambitiously enough, the series will not achieve its potential.
Since participants notice and respond to each other’s participation levels, rising passivity would be self-reinforcing. Fortunately, in the same way, rising ambition would be self-reinforcing too.
The next AI Safety Summit is an important opportunity not only to sustain, but to reinforce the momentum generated by the first summit.
Creating shared clarity on the need for progress in AI safety
A valuable goal for the next summit would be to create shared clarity on the need for progress in AI safety. Although the first summit has helped to build this clarity, the subject is still new for most participants and substantial ambiguity remains. Greater clarity would allow participants to more fully appreciate the importance of the summit series. It would also facilitate more productive discussions.
More specifically, the summit could aim to create shared clarity about both (a) the risks AI might pose and (b) the ways in which the world is and is not prepared to handle these risks. Understanding these factors together makes it possible to see how much progress urgently needs to be made.
To increase clarity about risks, the summit organisers can:
- Disseminate preliminary findings from the International Scientific Report on Advanced AI Safety: A major outcome of the first summit was a commitment to produce a “State of the Science” report (later renamed to the “International Scientific Report on Advanced AI Safety”), which will serve as the first authoritative summary of evidence regarding risks from frontier AI. The Korean summit is a natural opportunity to disseminate, explain, and discuss preliminary findings from the report. Research institutes such as the UK AI Safety Institute can also present new scientific results that go beyond those included in the report.
To increase clarity about preparedness, the summit organisers can:
- Hold discussions on “preparedness gaps”: Currently, there are many ways in which the world is not prepared to manage risks from increasingly advanced frontier AI. For instance, there are deficiencies in current misuse prevention techniques, risk assessment procedures, auditing and certification services, safety standards, and regulatory regimes. The summit could host discussions on these preparedness gaps to raise awareness and understanding.
- Produce or commission reports on “preparedness gaps”: The summit organisers could also produce or commission short reports on these gaps ahead of the summit, to inform discussions. Alternatively, they could commission a report assessing global preparedness for risks from advanced AI, as a complement to the report outlining the current state of the evidence on such risk. This would mirror the International Panel on Climate Change’s focus not just on the likely impacts of climate change, but also potential mitigation and adaptation measures.
Showcasing progress since the last summit
If the next summit can showcase progress since the first AI Safety Summit — held only around six months prior — then it can reinforce the ambition of participants. Meaningful progress would allow participants to see that, with enough effort, core AI safety challenges are tractable.
To this end, the summit organisers can:
- Invite research institutes to share research progress: This may involve presentations or short reports summarising recent progress in areas such as model evaluations and interpretability. Researchers at the UK AI Safety Institute or the US AI Safety Institute could be especially well-placed to prepare overviews. The US AI Safety Institute might also have made significant progress by this point.
- Invite companies to share updated reports on their safety practices and safety commitments: The first summit successfully convinced several frontier AI companies to prepare reports on their efforts to adopt responsible development and release practices. These responses often alluded to ongoing initiatives to refine and improve current practices. The next summit is an opportunity for companies to produce updated reports, which include further information and highlight progress they have made over the previous half-year. The updated reports could also potentially introduce explicit commitments to following certain especially important practices, analogous to the White House commitments companies have previously made. More AI companies, particularly companies outside the US and UK, could also be encouraged to produce these reports. Relatedly, the summit organisers could produce an updated version of the best practices report “Emerging Processes for Frontier AI Safety” that was prepared for the first summit.
- Invite governments to give progress reports on their safety initiatives: In the six months since the last summit, a number of governments are likely to have made meaningful progress in developing their own safety initiatives. For example, the UK will have more fully established the Safety Institute it announced at the previous summit. US agencies will have begun to implement the executive order on AI that was announced around the summit. The EU will be able to provide an update on the finalized EU AI Act and its AI Office. Multiple other countries, including Japan, may also have launched safety institutes by this time. The summit would be a natural venue for sharing progress updates on these kinds of initiatives. It could also be a natural venue for announcing new initiatives.
Beginning to build a long-term vision and roadmap for the series
The first summit produced a consensus statement — the Bletchley Declaration — that suggested high-level goals for future summits. The statement notes that the “agenda for our cooperation” will focus on “identifying AI safety risks of shared concern” and “building respective risk-based policies across our countries to ensure safety.”
However, the statement only briefly elaborates on these goals. It also does not say much about how future summits will work toward achieving them.
It could be valuable, then, to develop a fuller vision of what the series aims to achieve, along with a roadmap that describes how the series can fulfill this vision. This kind of vision and roadmap could increase the ambition of participants, by helping them understand what their continued participation can produce. A vision and roadmap would also support more effective summit planning in future years.
To take steps in this direction, the summit organisers could:
- Propose more detailed statements on series goals, to include in the next communique: For example, one more specific goal could be to support the creation of international standards regarding the responsible development and release of frontier AI systems.
- Begin to identify forward processes: Most ambitious summit goals will take many years of work to achieve. To ensure they are achieved, then, it will often make sense to set up processes that are designed to drive progress forward across multiple summits. For example, suppose that one goal is to support the creation of responsible development and release standards. This goal could be furthered by the annual solicitation of safety practice reports by frontier AI companies, perhaps combined with annual commentaries on these reports by independent experts.
- Have companies commit to continuing to develop, share, and adhere to AI safety policies: One possible “forward process,” as alluded to above, could involve companies continuing to iterate on the safety policies they shared at the first summit. To this end, the summit organisers could encourage companies to explicitly commit to iterating on their policies and sharing updated versions at each summit. Companies could also be encouraged to explicitly commit to adhering to their safety policies. Summit organisers could partly steer the iterative process by identifying questions that they believe it would be especially valuable for safety policies to address. Having companies commit to capability-based thresholds or safety policies seems particularly promising (similar to Anthropic’s Responsible Scaling Policy and OpenAI’s Beta Preparedness Plan).
- Commit to continuing to update the International Scientific Report on Advanced AI Safety: Another specific “forward process” could be a plan to produce recurring updates to the report, for instance on a once-a-year cadence. A continually evolving International Scientific Report on Advanced AI Safety could serve as a cornerstone of future summits and, more generally, global efforts to understand risks from frontier AI systems.
- Launch a new working group to explore the need for new international institutions: In general, the summit could contribute to the development of a roadmap by launching working groups that investigate relevant questions. One especially key question is whether any new international institutions might ultimately be needed to address emerging risks from frontier AI. There has been some early academic work on this question. The UN’s AI Advisory Body recently put out an interim report that clarifies functions that international institutions (whether they are new or existing) will need to fulfil. However, there is currently nothing approaching an authoritative investigation of whether the successful governance of frontier AI systems will require creating new international institutions. If a credible working group does conclude that some new institutions may be needed (e.g. an “IPCC for AI”), then this would naturally inform the summit roadmap.
Conclusion
The AI Safety Summit series will likely run for many years. It could produce tremendous value. However, like many international forums, it could also sputter out.
The Korean AI Safety Summit — the first follow-up to the initial summit — is a key opportunity to ensure that the series lives up to its potential. It can reinforce the momentum produced by the initial summit and convince participants that they should approach the series ambitiously.
This underlying goal can be furthered by achieving three more concrete goals. In particular, it would be valuable for the next summit to: (1) create shared clarity on the need for progress in AI safety, (2) showcase progress since the last summit, and (3) begin to build a long-term vision and roadmap for the series.