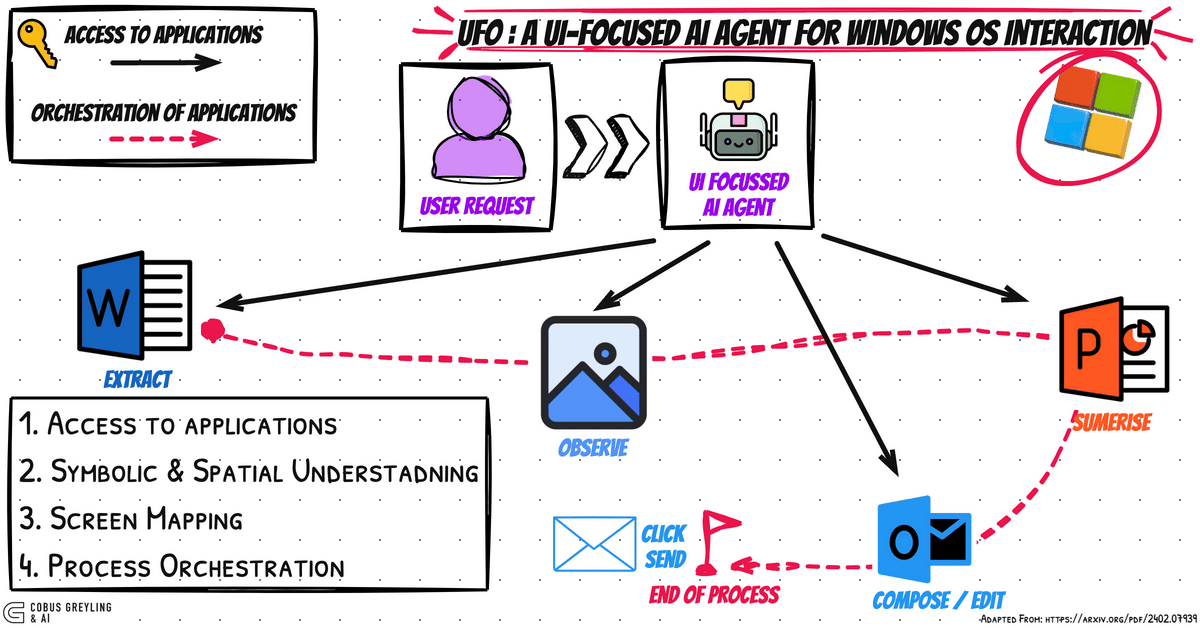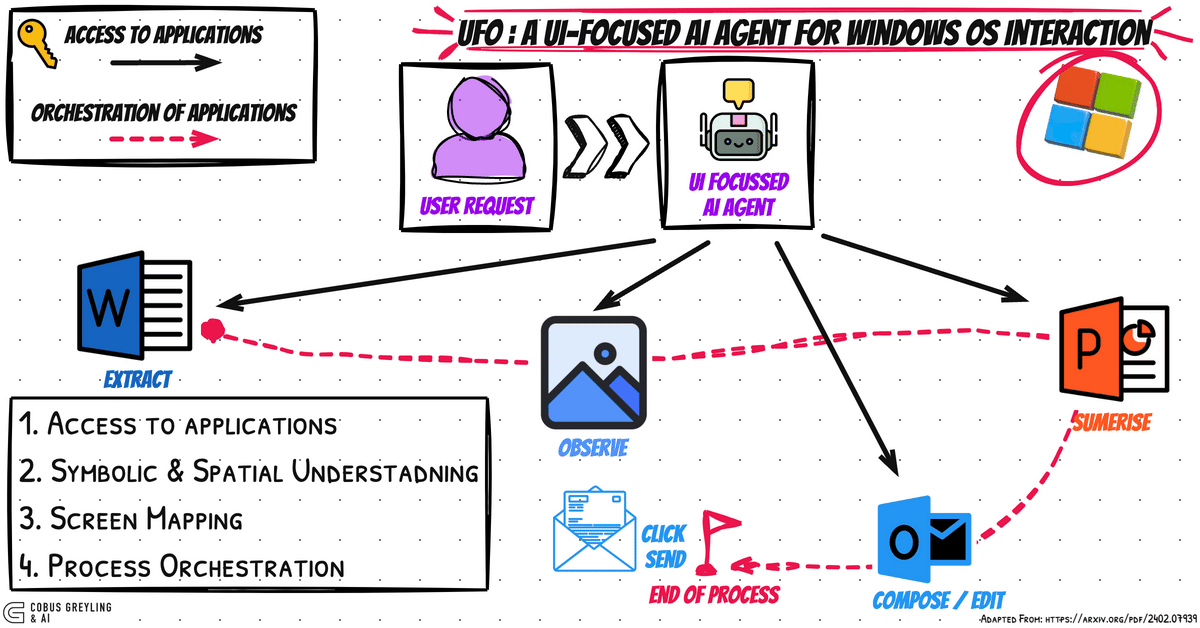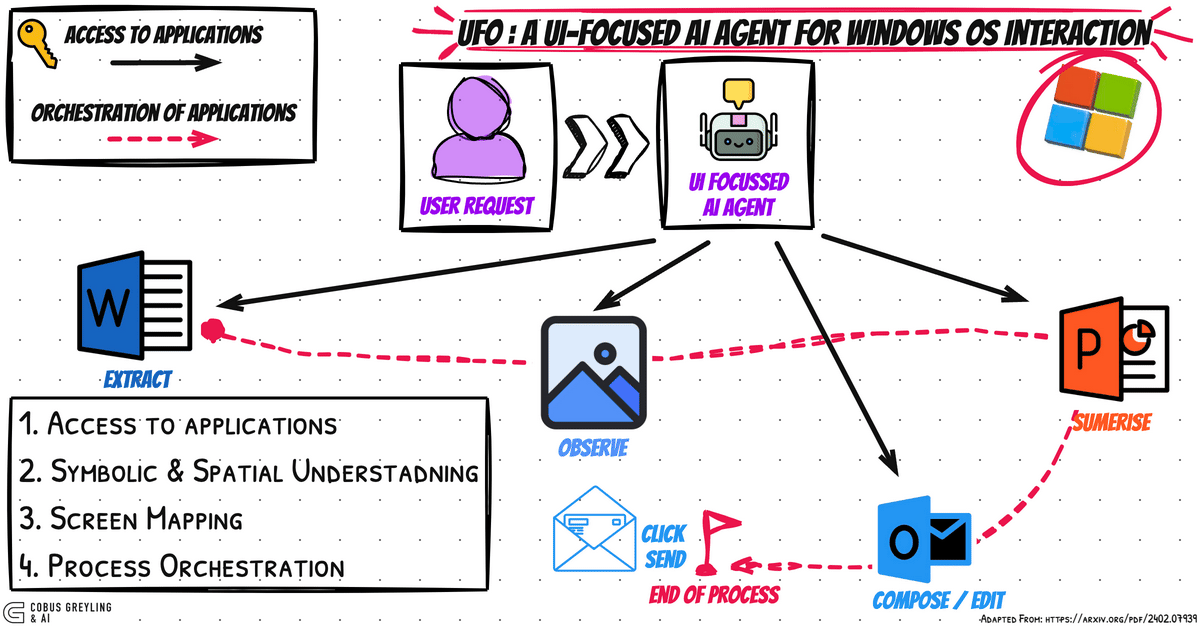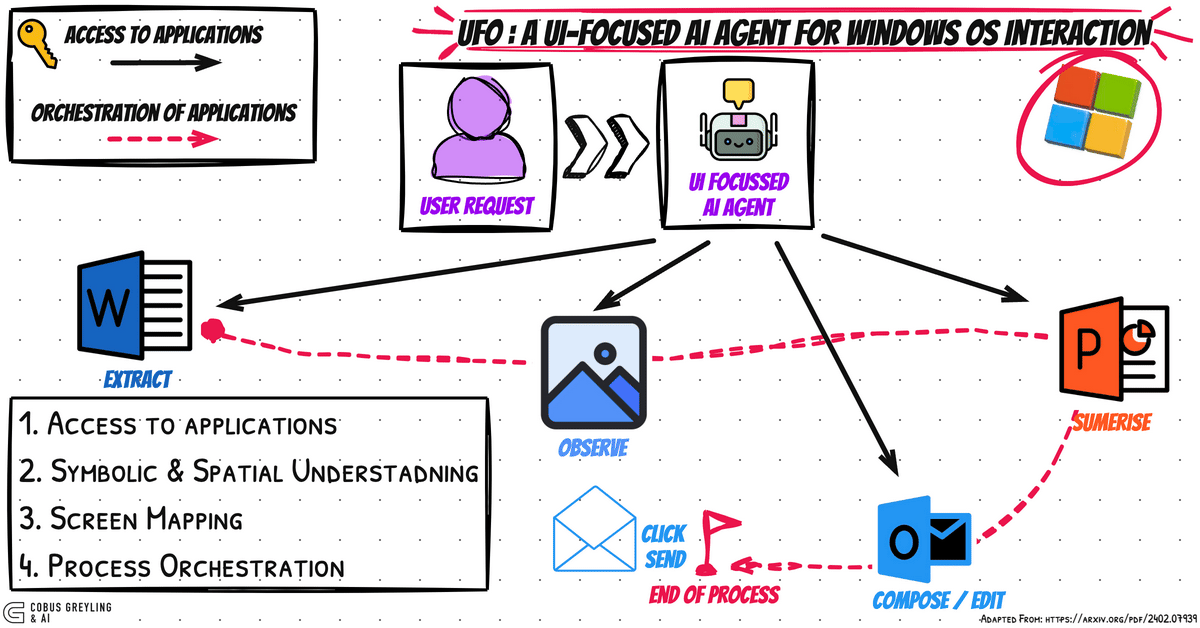
Mastering Git
A powerful Git feature for temporarily saving code in progress
Imagine discovering a critical bug that needs an immediate fix while you are working halfway through a code change. Your attempt to switch branch fails because of uncommitted changes in your current feature branch. These changes aren’t ready for a commit but are too valuable to discard. In such a situation where you need to switch contexts quickly, git stash offers an elegant solution to temporarily store your unfinished code safely without committing. In this post, we will explore how to use git stash effectively.
Imagine we are writing a letter with a pen and a paper, but suddenly we had to write another more urgent letter and send it away. Our desk can hold only one letter. It would be too wasteful to throw our unfinished letter since it took us some time to write what’s written so far. Instead of throwing it away, we can put it away in a secure chest so that we can pick it up and continue once we finish this more time-sensitive letter. This will allow us to get straight on to writing this more urgent letter and send it quickly while saving our work on the other letter. In this analogy, halfway written letter is the uncommitted…