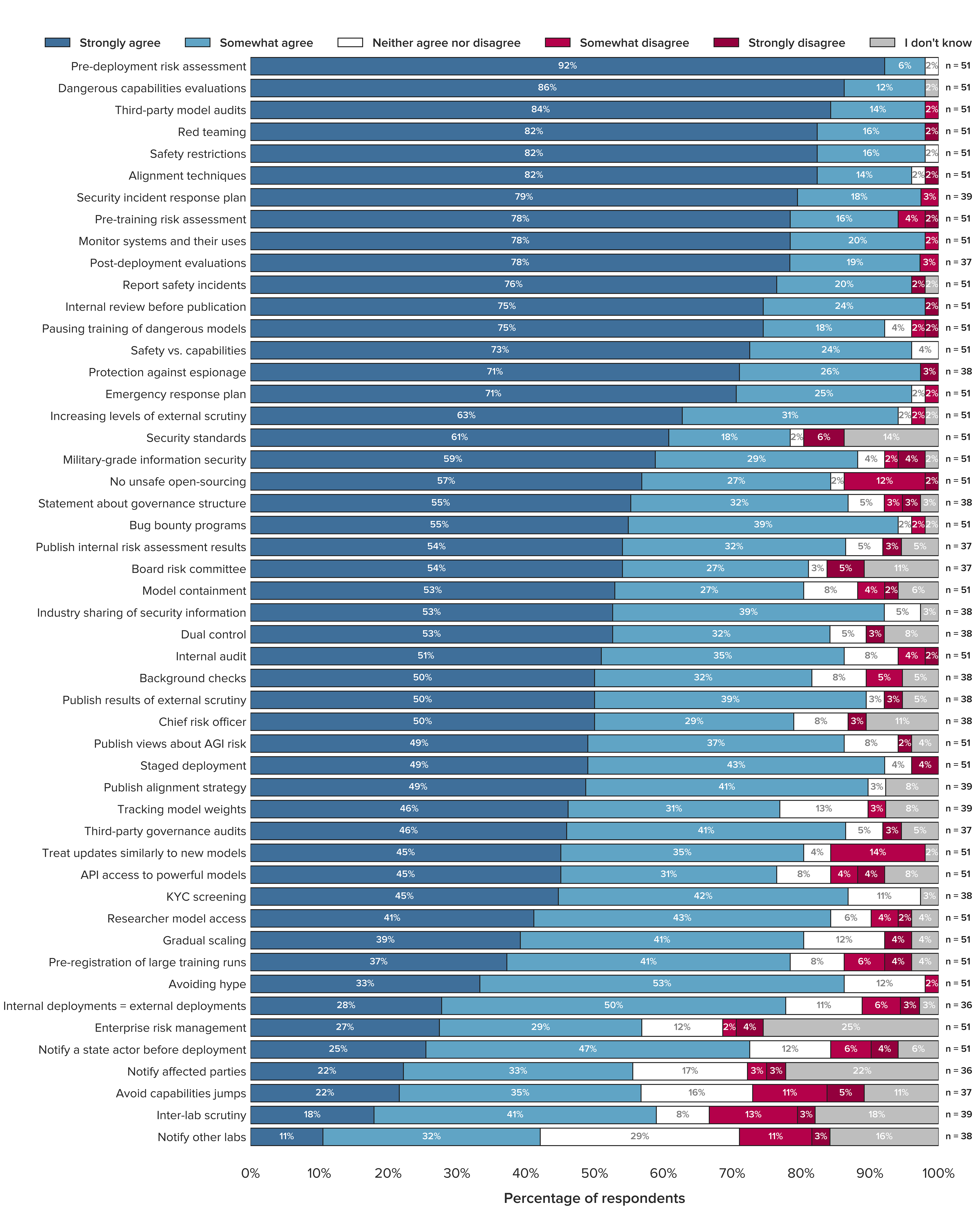
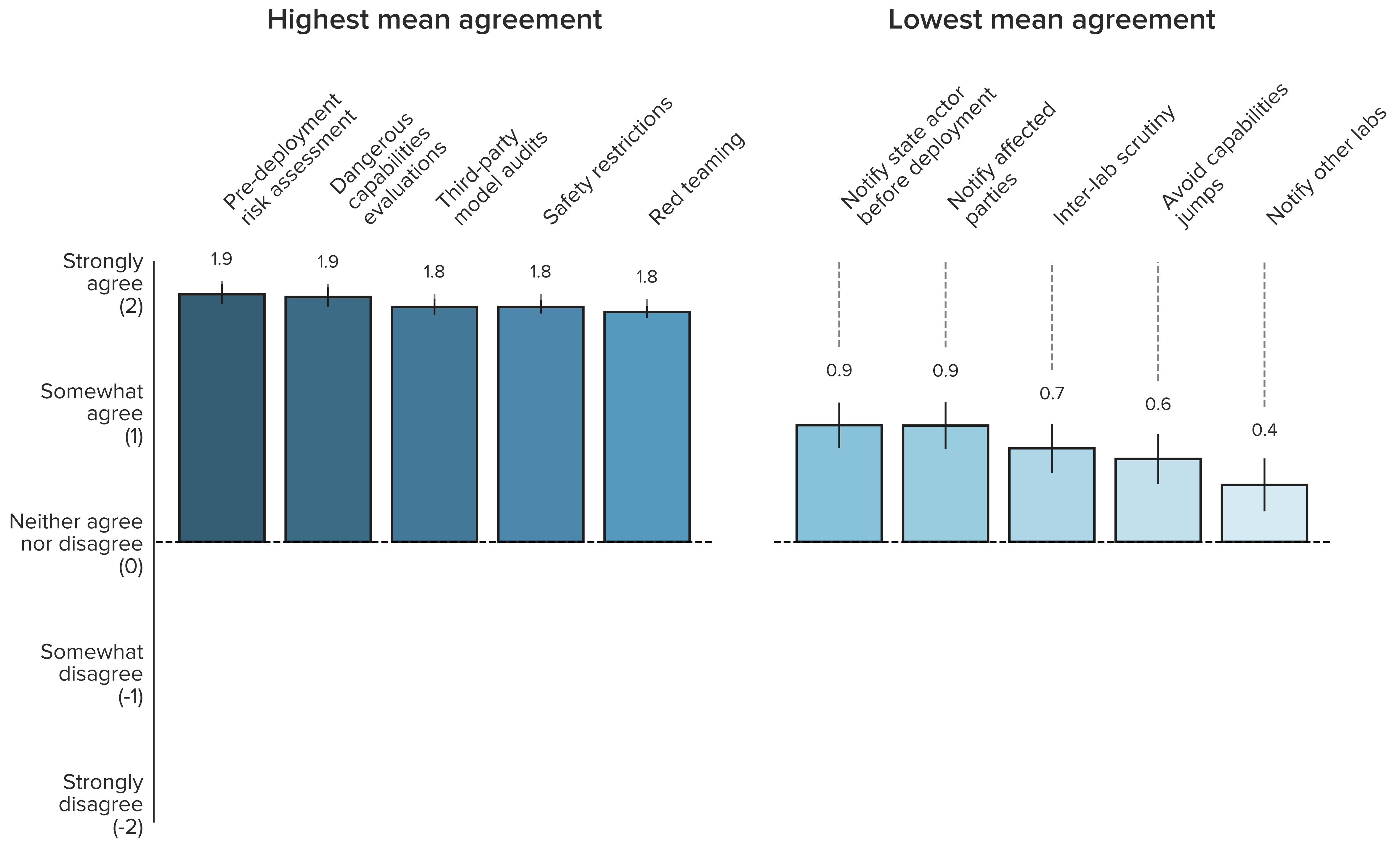
This post summarises and analyses two recent Beijing policy documents.
GovAI research blog posts represent the views of their authors, rather than the views of the organisation.
New Chinese policy interest in general AI
Historically, developing general artificial intelligence systems has not been an explicit priority for policymakers in the People’s Republic of China (PRC). The State Council’s 2017 New Generation Artificial Intelligence Development Plan and subsequent documents rarely mention general systems — even as Chinese interest in companies aiming to develop them, such as OpenAI, has grown steadily.
That appears to be changing. A group of the country’s most senior policymakers signalled a shift in the government’s views on AI in late April, 2023. For the first time, a readout from a meeting of the 24-member Politburo — bringing together key officials from the Party, State, and People’s Liberation Army — promoted the development of “general artificial intelligence systems” (通用人工智能):1
[The meeting pointed out that] importance should be attached to the development of general artificial intelligence, an [associated] innovation ecosystem should be constructed, and importance should be attached to risk prevention.
[会议指出] 要重视通用人工智能发展,营造创新生态,重视防范风险。
Subsequent technology development plans put out by Beijing’s powerful local government focus on support for general AI and large model development. These place particular emphasis on overcoming barriers — likely heightened by recent US-led export controls — to accessing the large volume of compute that large model training requires. One of the documents describes meeting compute needs as “urgent” (紧迫). In addition to insufficient access to compute, an inadequate supply of high-quality data is identified as a key constraint on future progress.
The documents outline plans for an array of measures including subsidies, aggregation of existing compute and data for large model developers, and more research on advanced AI algorithms in an attempt to mitigate existing compute and data bottlenecks. The documents also contain sections on increasing research in AI ethics and safety, foreshadowing a recent statement from Xi Jinping calling for “a raised level of AI safety governance.”
Beijing’s AI policy priorities
The Beijing municipal government is leading the implementation of the PRC’s policy shift. It has significant power to shape the country’s AI industry: the city hosts many of the country’s most advanced AI companies and institutes, such as the Beijing Academy of Artificial Intelligence, and its municipal government cooperates with national institutions to support them.
The municipal government released a set of “Measures to Promote General Artificial Intelligence Innovation and Development in Beijing” and a “General Artificial Intelligence Industry Innovation Partnership Plan” in the weeks following the Politburo announcement. These documents serve as concrete policy implementation guidelines for government bodies and set several priorities:
1. Increasing the availability of advanced computing power
The Beijing government is looking to ameliorate the shortage of “high-quality computing resources” (高质量算力资源) facing large model teams in the city. The city’s science and economic policy bodies will seek to create a “compute partnership” (算力伙伴) between Aliyun — Alibaba Group’s cloud compute subsidiary — and the Beijing Supercomputing Cloud Center to subsidise and aggregate compute. The documents suggest that large model teams based in the city would then have priority access. In a potential signal that Beijing companies are already struggling to locate sufficient compute for their goals, the city government plans to draw on additional compute resources from adjacent provinces such as Tianjin and Hebei to meet these goals.
2. Increasing the supply of high-quality training data
The municipal government wants to increase the supply of high-quality data to its leading large model developers. Policy measures announced here include a “data partnership” (数据伙伴) with nine initial members including the Beijing Big Data Centre (北京市大数据中心), as well as a trading platform to lower barriers to acquiring high-quality data for large model teams. The municipal government seems to also intend to support the building of high-quality training data collections, to explore making more of its own vast data reserves available for large model training, and to create a platform for crowdsourcing data labelling.
3. Supporting algorithmic research
Beijing’s government states that it will aim to help its research institutions develop key algorithmic innovations. This includes general improvements in efficiency, but also more research on basic theories for reasoning and agentic behaviour, as well as research on alternative paradigms for developing general AI systems.
4. Increasing safety and oversight for large model development
The municipal government wants to see independent, non-profit third parties create model evaluation benchmarks and methods. Models that have “social mobilisation capabilities” (社会动员能力) — i.e. models which can influence public opinion at scale — will need to undergo security assessments by regulators. Interestingly, the municipal government also seems keen on more work on “intent alignment” (人类意图对齐), a critical pillar of AI safety research at some of the companies developing leading large models.
Conclusion
These recent policy developments, at both the local and national levels, represent a clear policy shift in the PRC towards the technological paradigms being pursued by Western AI companies such as DeepMind and OpenAI. PRC policymaker concern about a shortage of advanced compute is also a clear signal that recent export controls on this technology, imposed by the United States and allied nations, are stymieing a new plank of Chinese industrial policy.
Whether PRC policymakers can realistically overcome this barrier is unclear. It also remains to be seen whether policymakers in Beijing will create strong oversight mechanisms and safeguards to mitigate risks — from AI weaponization and AI-enabled misinformation to hypothesised extreme risks from future systems — that are garnering mounting concern.