Mobile applications are integral to daily life, serving myriad purposes, from entertainment to productivity. However, the complexity and diversity of mobile user interfaces (UIs) often pose challenges regarding accessibility and user-friendliness. These interfaces are characterized by unique features such as elongated aspect ratios and densely packed elements, including icons and texts, which conventional models struggle to interpret accurately. This gap in technology underscores the pressing need for specialized models capable of deciphering the intricate landscape of mobile apps.
Existing research and methodologies in mobile UI understanding have introduced frameworks and models such as the RICO dataset, Pix2Struct, and ILuvUI, focusing on structural analysis and language-vision modeling. CogAgent leverages screen images for UI navigation, while Spotlight applies vision-language models to mobile interfaces. Models like Ferret, Shikra, and Kosmos2 enhance referring and grounding capabilities but mainly target natural images. MobileAgent and AppAgent employ MLLMs for screen navigation, indicating a growing emphasis on intuitive interaction mechanisms despite their reliance on external modules or predefined actions.
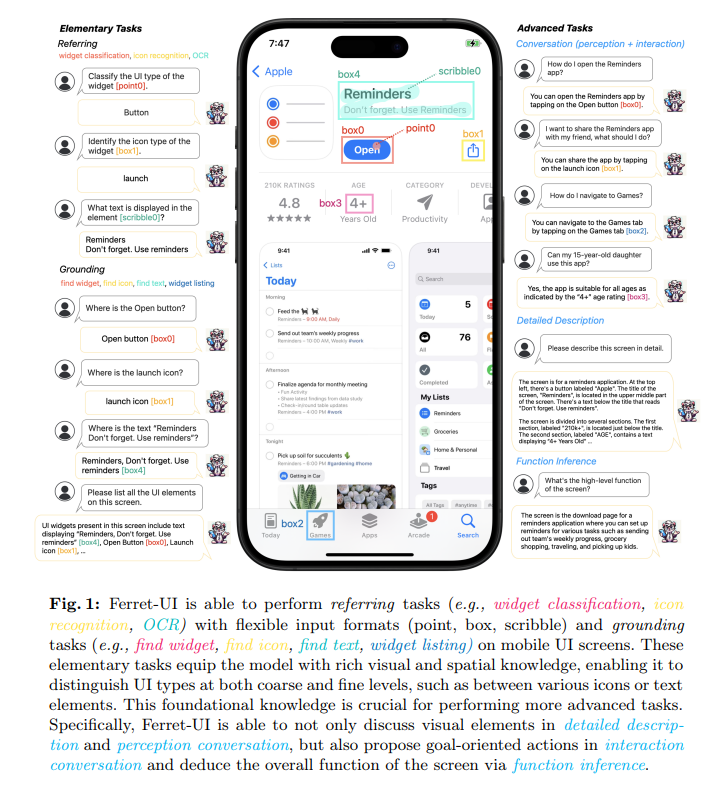
Apple researchers have introduced Ferret-UI, a model specifically developed to advance the understanding and interaction with mobile UIs. Distinguishing itself from existing models, Ferret-UI incorporates an “any resolution” capability, adapting to screen aspect ratios and focusing on fine details within UI elements. This approach ensures a deeper, more nuanced comprehension of mobile interfaces.
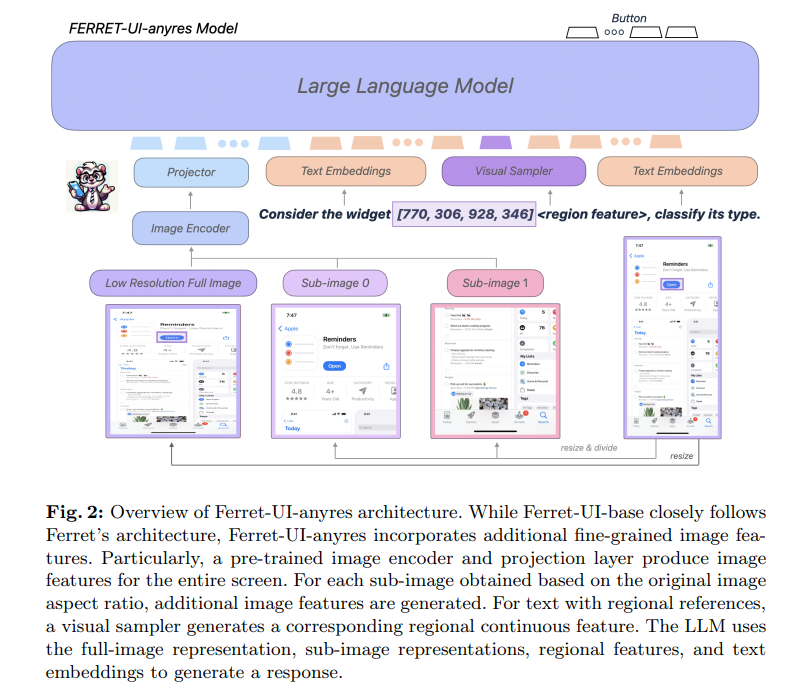
Ferret-UI’s methodology revolves around adapting its architecture for mobile UI screens, utilizing an “any resolution” strategy for handling various aspect ratios. The model processes UI screens by dividing them into sub-images, ensuring detailed element focus. Training involves the RICO dataset for Android and proprietary data for iPhone screens, covering elementary and advanced UI tasks. This includes widget classification, icon recognition, OCR, and grounding tasks like find widget and find icon, leveraging GPT-4 for generating advanced task data. The sub-images are encoded separately, using visual features of varying granularity to enrich the model’s understanding and interaction capabilities with mobile UIs.
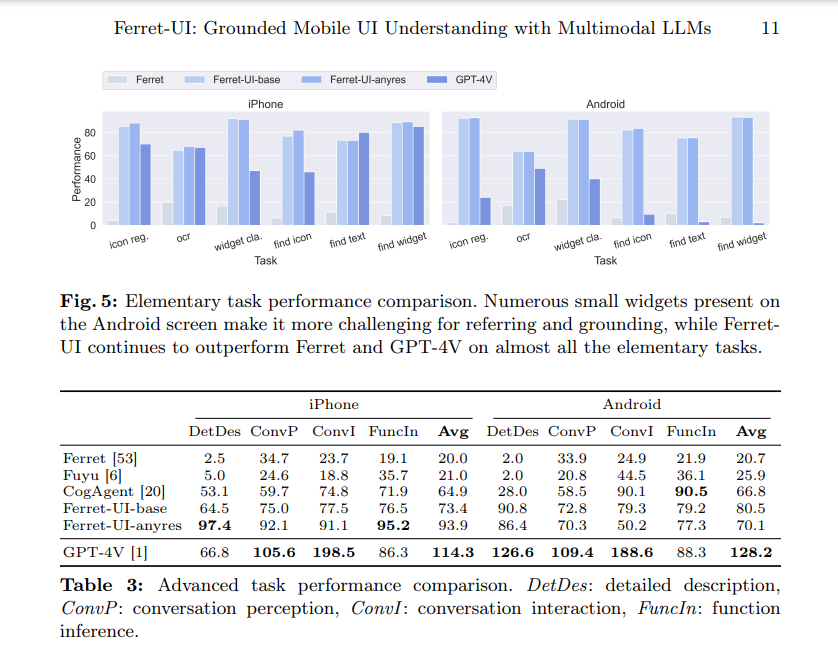
Ferret-UI is more than just a promising model; it’s a proven performer. It outperformed open-source UI MLLMs and GPT-4V, exhibiting a significant leap in task-specific performances. In icon recognition tasks, Ferret-UI reached an accuracy rate of 95%, a substantial 25% increase over the nearest competitor model. It achieved a 90% success rate for widget classification, surpassing GPT-4V by 30%. Grounding tasks like finding widgets and icons saw Ferret-UI maintaining 92% and 93% accuracy, respectively, marking 20% and 22% improvement compared to existing models. These figures underline Ferret-UI’s enhanced capability in mobile UI understanding, setting new benchmarks in accuracy and reliability for the field.
In conclusion, the research introduced Ferret-UI, Apple’s novel approach to improving mobile UI understanding through an “any resolution” strategy and a specialized training regimen. By leveraging detailed aspect-ratio adjustments and comprehensive datasets, Ferret-UI significantly advanced task-specific performance metrics, notably exceeding those of existing models. The quantitative results underscore the model’s enhanced interpretative capabilities. But it’s not just about the numbers. Ferret-UI’s success illustrates the potential for more intuitive and accessible mobile app interactions, paving the way for future advancements in UI comprehension. It’s a model that can truly make a difference in how we interact with mobile UIs.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter. Join our Telegram Channel, Discord Channel, and LinkedIn Group.
If you like our work, you will love our newsletter..
Don’t Forget to join our 40k+ ML SubReddit
Nikhil is an intern consultant at Marktechpost. He is pursuing an integrated dual degree in Materials at the Indian Institute of Technology, Kharagpur. Nikhil is an AI/ML enthusiast who is always researching applications in fields like biomaterials and biomedical science. With a strong background in Material Science, he is exploring new advancements and creating opportunities to contribute.