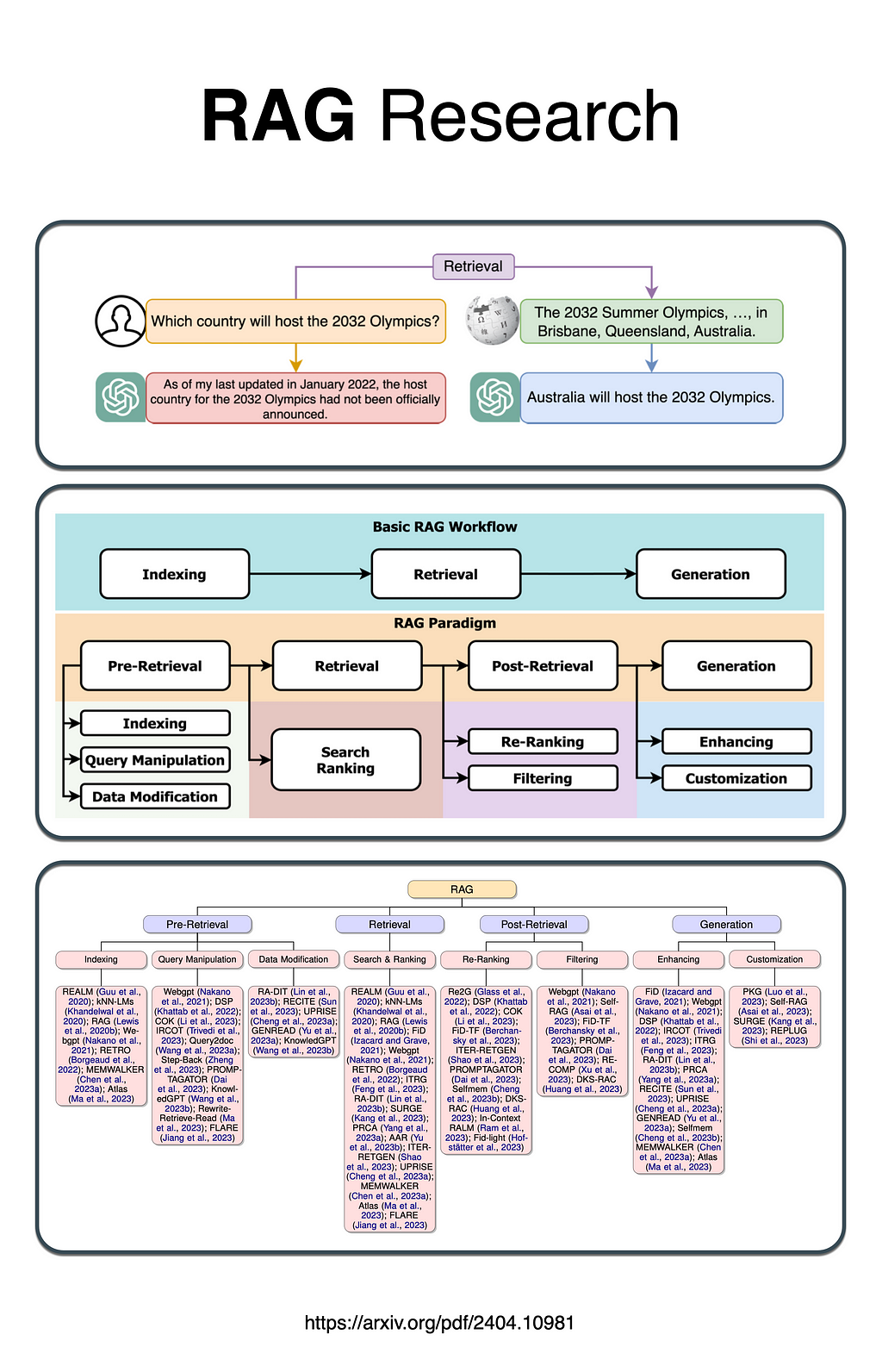
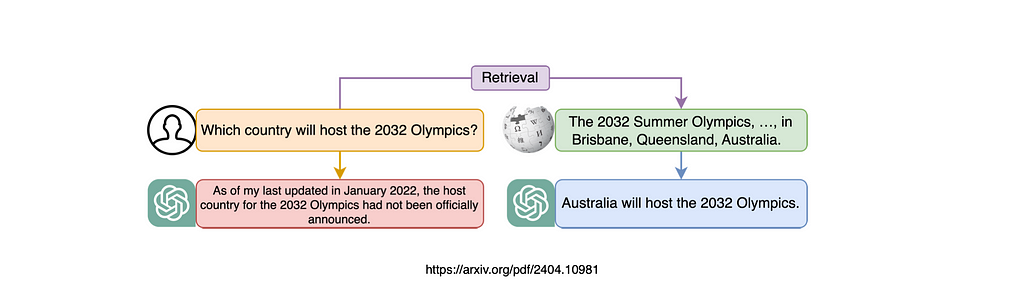
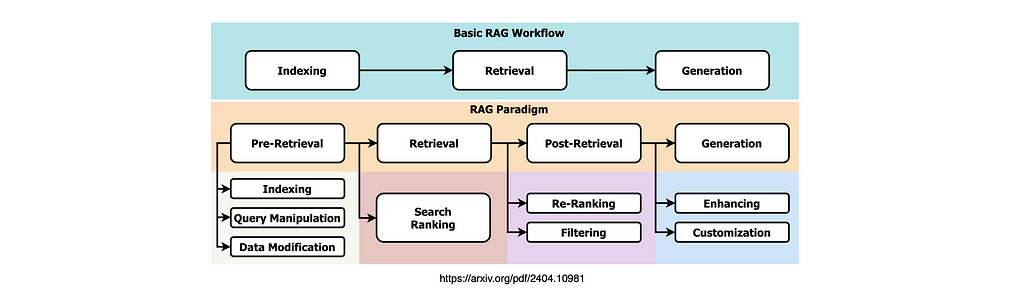
Applying existing literature to a practical case
Can we predict the extinction of a language? It doesn’t sound easy, and it indeed shouldn’t, but it shouldn’t stop us from trying to model it.
I was recently interested in this topic and started reviewing some of the existing literature. I came across one article[1] that I…