This blog post summarises the recent working paper “Increased Compute Efficiency and the Diffusion of AI Capabilities” by Konstantin Pilz, Lennart Heim, and Nicholas Brown.
GovAI research blog posts represent the views of their authors rather than the views of the organisation.
Introduction
The compute needed to train an AI model to a certain performance gets cheaper over time. In 2017, training an image classifier to 93% accuracy on ImageNet cost over $1,000. In 2021, it cost only $5 — a reduction of over 99%. We describe this decline in cost — driven by both hardware and software improvements — as an improvement in compute efficiency.
One implication of these falling costs is that AI capabilities tend to diffuse over time, even if leaders in AI choose not to share their models. Once a large compute investor develops a new AI capability, there will usually be only a short window — a critical period — before many lower-resource groups can reproduce the same capability.
However, this does not imply that large compute investors will have their leads erode. Compute efficiency improvements also allow them to develop new capabilities more quickly than they otherwise would. Therefore, they may push the frontier forward more quickly than low-resource groups can catch up.
Governments will need to account for these implications of falling costs. First, since falling costs will tend to drive diffusion, governments will need to prepare for a world where dangerous AI capabilities are widely available — for instance, by developing defenses against harmful AI models. In some cases, it may also be rational for governments to try to “buy time,” including by limiting irresponsible actors’ access to compute.
Second, since leading companies will still tend to develop new capabilities first, governments will still need to apply particularly strong oversight to leading companies. It will be particularly important that these companies share information about their AI models, evaluate their models for emerging risks, adopt good information security practices, and — in general — make responsible development and release decisions.
The causes of falling costs
Falling training costs stem from improvements in two key areas:
- Advances in hardware price performance — as predicted by Moore’s Law — increase the number of computational operations that a dollar can buy. Between 2006 and 2021, the price performance of AI hardware doubled approximately every two years.
- Advances in algorithmic efficiency decrease the number of computational operations needed to train an AI model to a given level of performance. For example, between 2012 and 2022, advances in image recognition algorithms halved the compute required to achieve 93% classification accuracy on the ImageNet dataset every nine months.
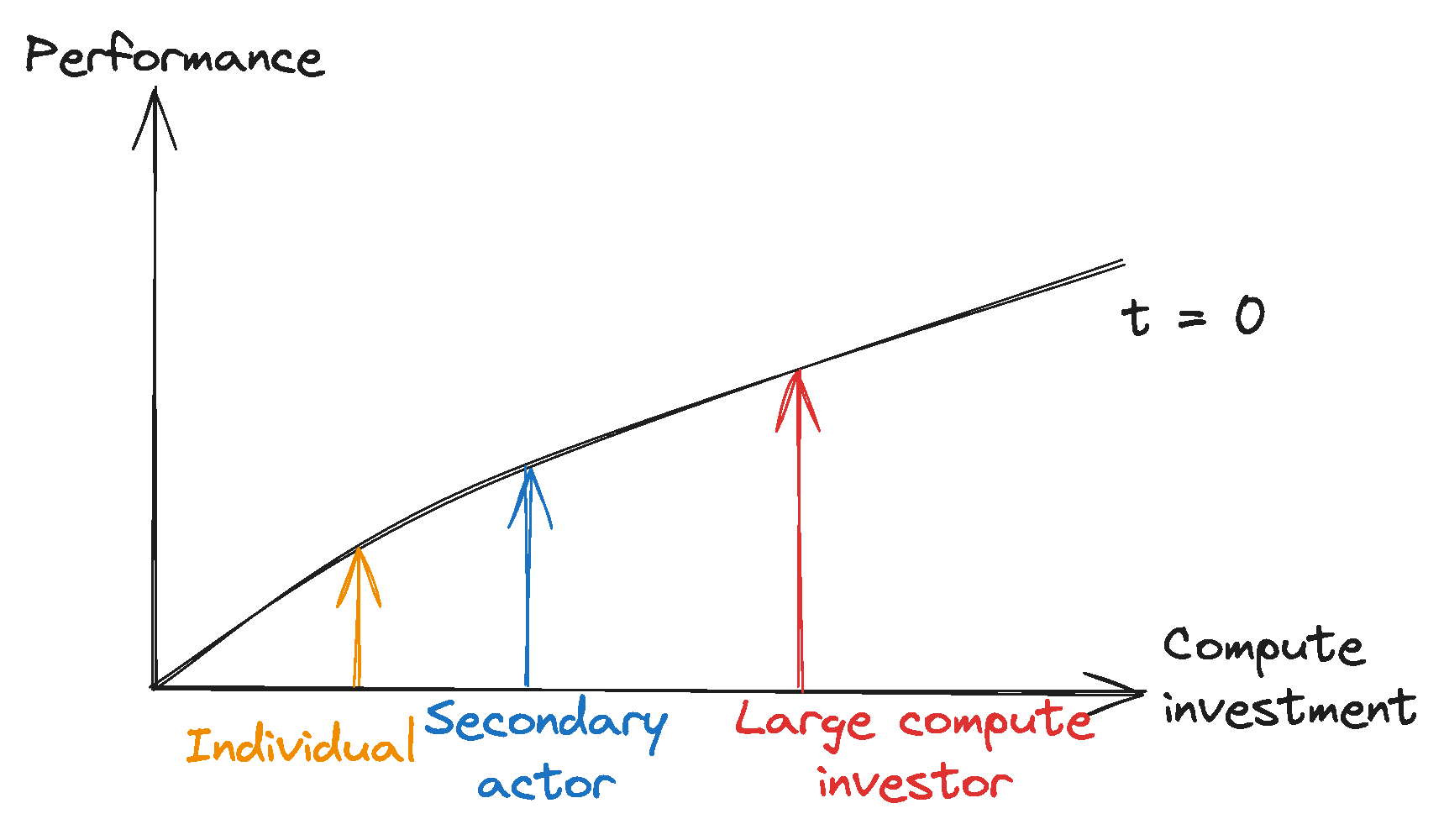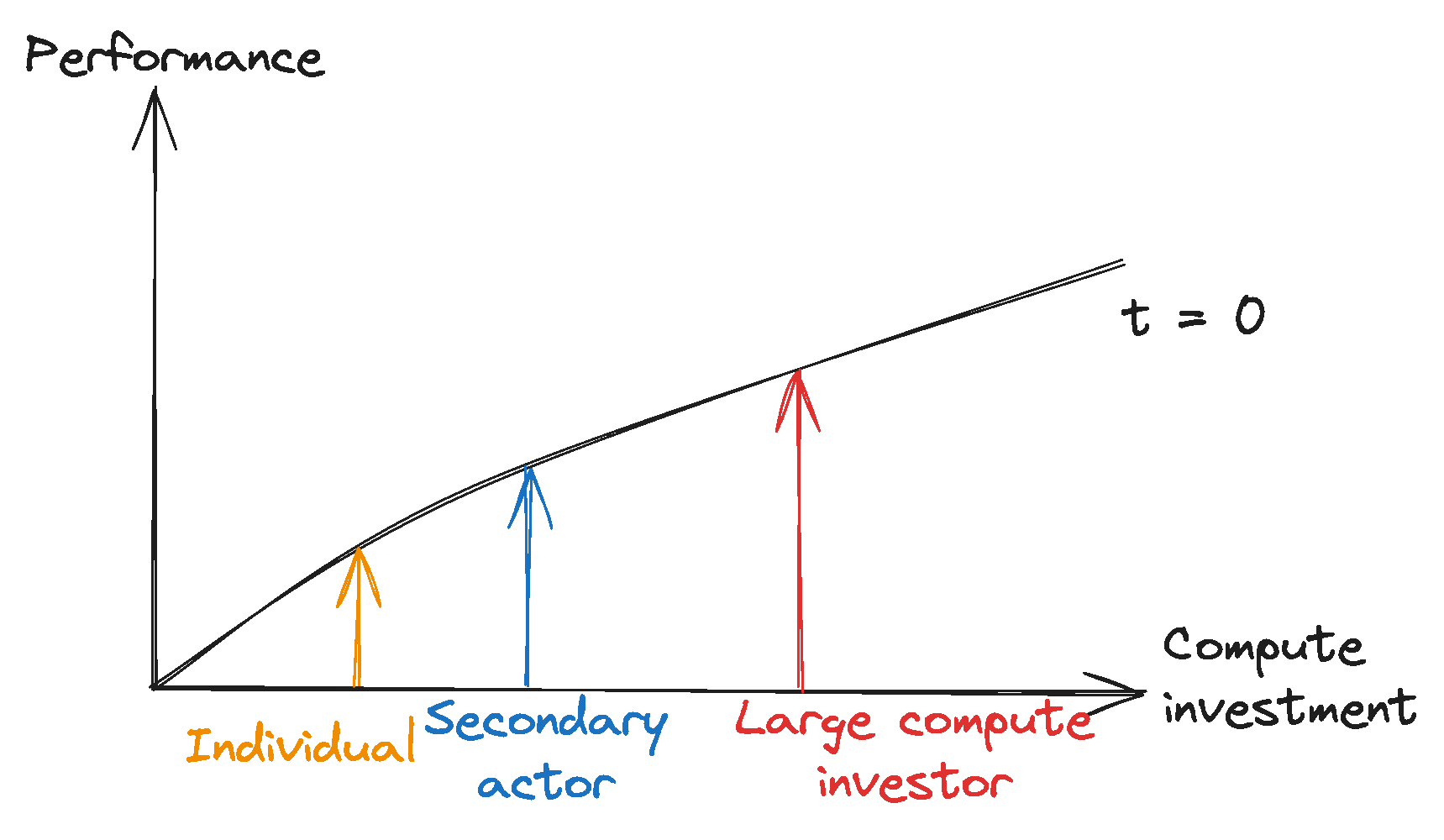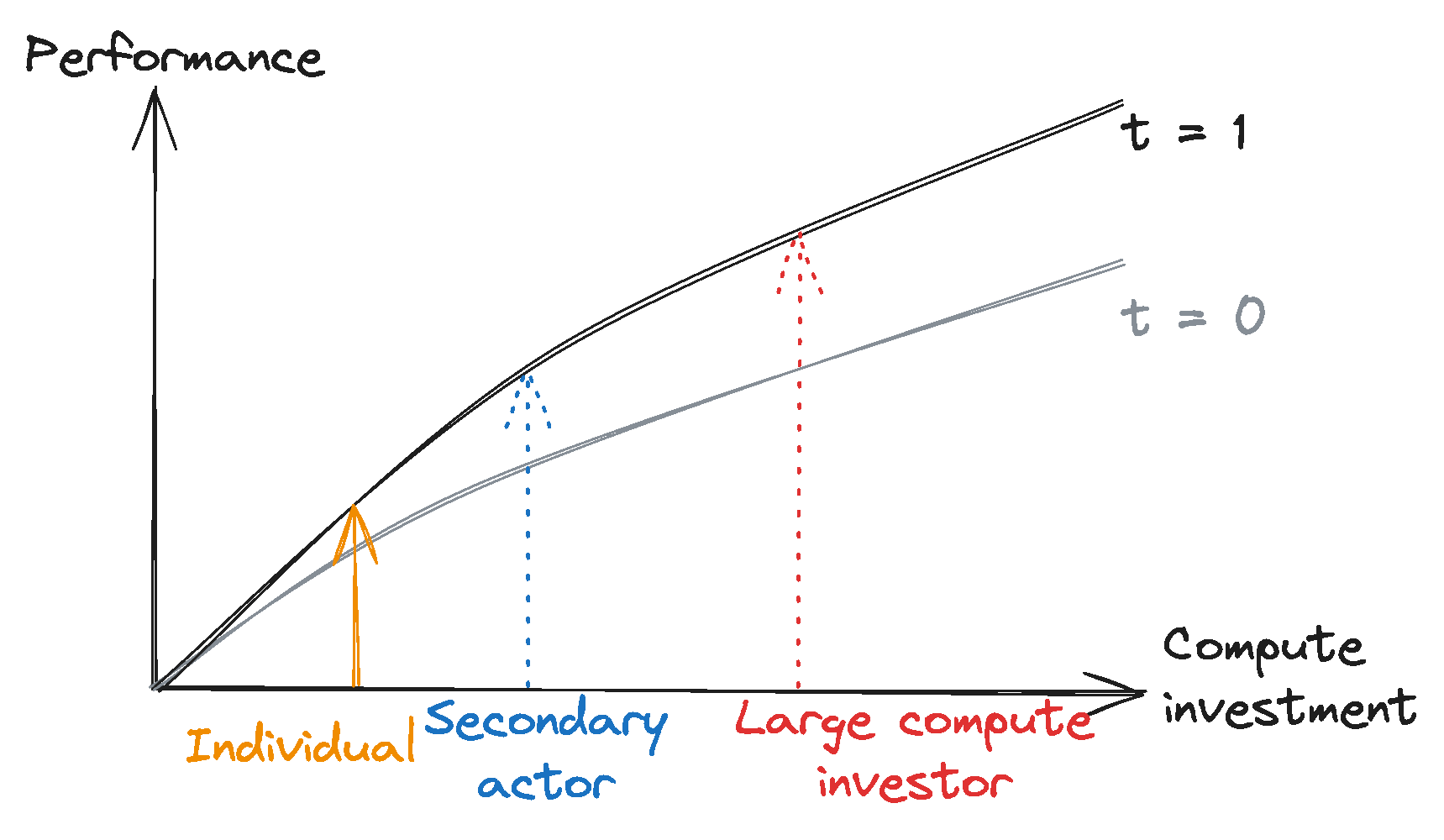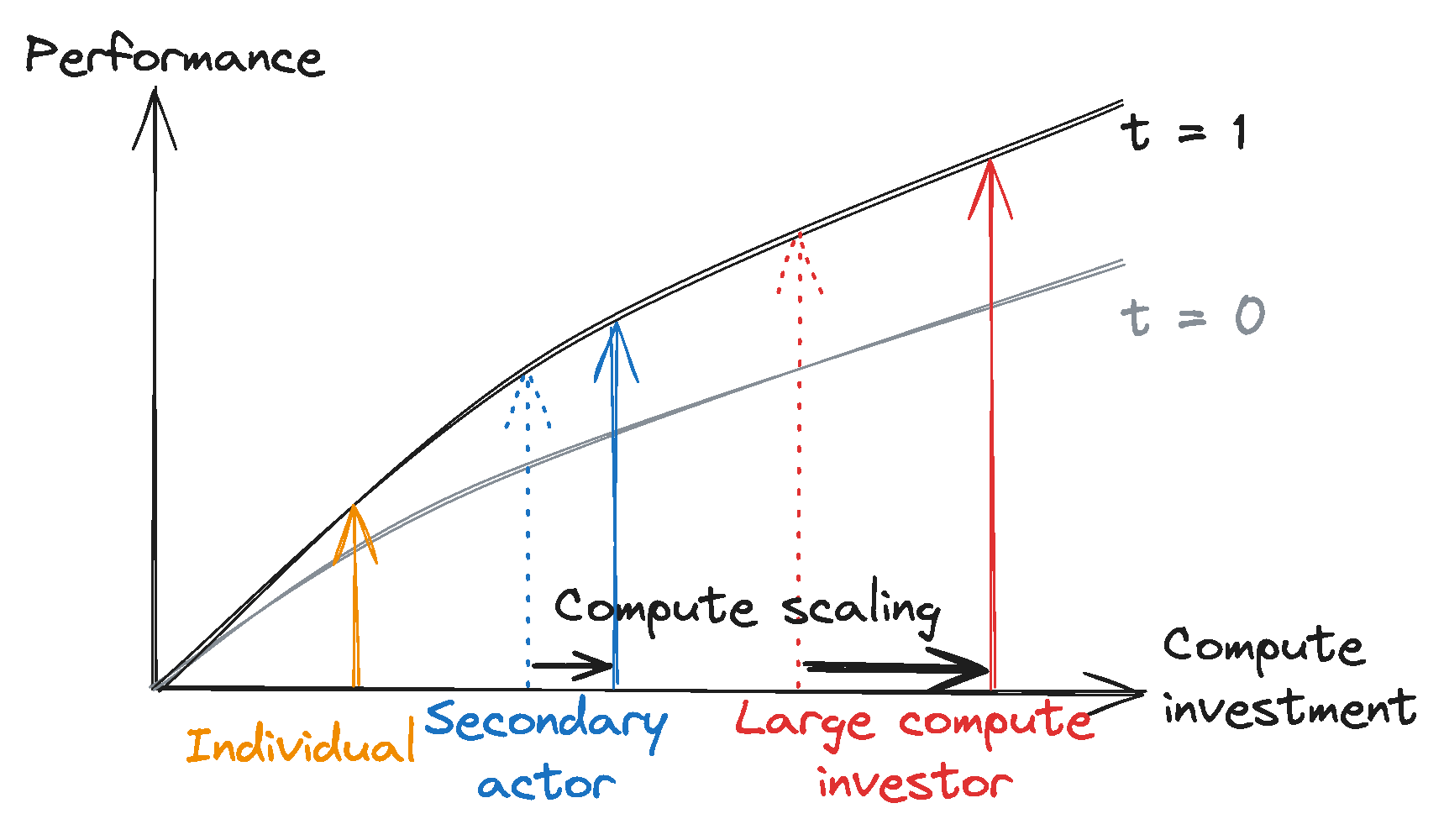
To capture the combined impact of these factors, we introduce the concept of compute investment efficiency — abbreviated to compute efficiency — which describes how efficiently investments in training compute can be converted into AI capabilities. Compute efficiency determines the AI model performance1 available with a given level of training compute investment, provided the actor also has sufficient training data (see Figure 1).
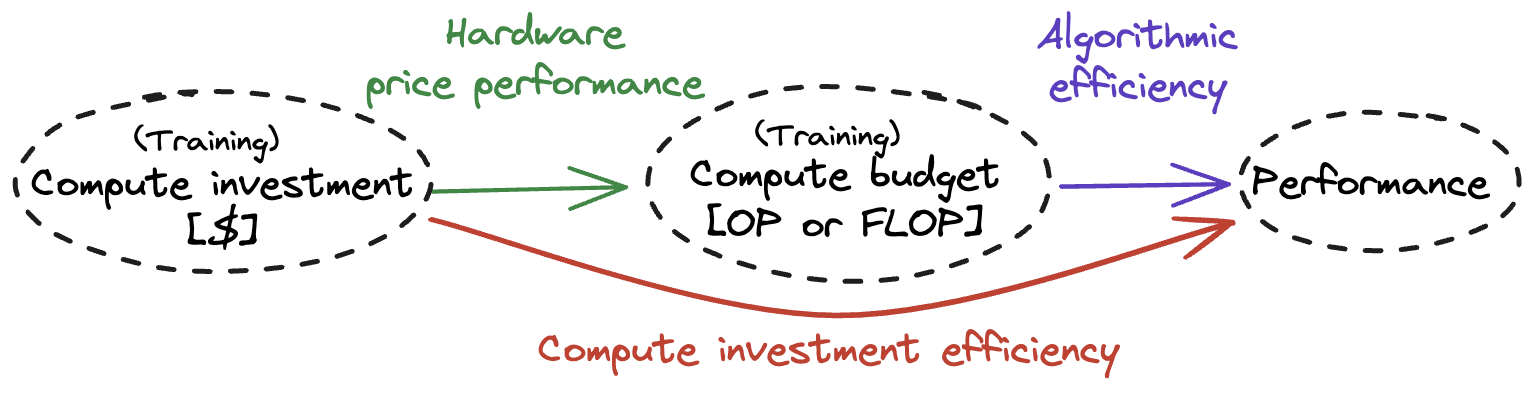
Access and performance effects
Based on our model, we observe that increasing compute efficiency has two main effects:2
- An access effect: Over time, access to a given level of performance requires less compute investment (see Figure 2, red).
- A performance effect: Over time, a given level of compute investment enables increased performance (see Figure 2, blue).
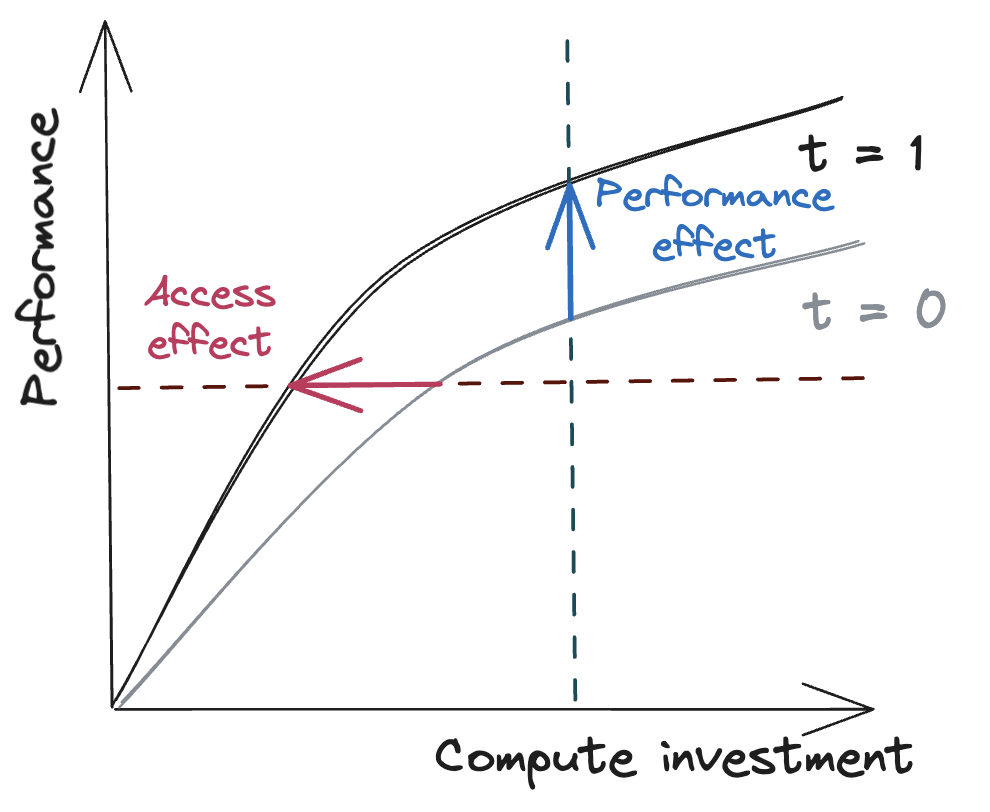
If actors experience the same compute efficiency improvements, then these effects have the following consequences:4
Capabilities diffuse over time. Due to the access effect, the investment required to reach a given performance level decreases over time, giving an increased number of actors the ability to reproduce capabilities previously restricted to large compute investors.
Large compute investors remain at the frontier. Since large compute investors achieve the highest performance levels, they are still the first to discover new model capabilities5 that allow novel use cases. Absent a ceiling on absolute performance, those actors also will continue to demonstrate the highest level of performance in existing capabilities.
The emergence and proliferation of dangerous capabilities
Future AI models could eventually show new dangerous capabilities, such as exploiting cybersecurity vulnerabilities, aiding bioweapon development, or evading human control. We now explore the discovery and proliferation of dangerous capabilities as compute efficiency increases.

Dangerous capabilities first appear in models trained by large compute investors. Since dangerous capabilities require high levels of performance, large compute investors likely encounter them first.6
These dangerous capabilities then proliferate over time, even if large compute investors limit access to their models. As compute efficiency improves, more actors can train models with dangerous capabilities. The dangerous capabilities can therefore proliferate even when large compute providers provide only limited or structured access to their models. This proliferation increases the chance of misuse and accidents.
Defensive tools based on leading models could potentially increase resilience against these dangerous capabilities. To counteract harm caused by weaker models, large compute investors may be able to use their more advanced models to create defensive tools.7 For example, cybersecurity tools powered by advanced models could find vulnerabilities before weaker models can exploit them. However, some domains, such as biotechnology, may greatly favor the offense, making it difficult to defend against dangerous deployments even with superior models.
Governance implications
Oversight of large compute investors can help to address the most severe risks, at least for a time. If the most severe risks from AI development originate from the most capable models and their large-scale deployment, then regulating large-scale compute users can — at least for a time — address the most severe risks. For instance, governments can require developers of large-scale models to perform dangerous capability evaluations and risk assessments, report concerning results, and use the results to make responsible release decisions. Governments can also encourage or require developers to implement good information security practices to prevent their models from leaking or being stolen. Furthermore, governments can develop the capability to quickly detect and intervene when models created by these developers cause harm.
Large compute investors should warn governments and help them prepare for the proliferation of advanced capabilities. The effectiveness of societal measures to mitigate harm from proliferation hinges on the time that passes between large compute investors discovering harmful capabilities and their proliferation to malicious or irresponsible actors. To effectively use this critical period, governments can implement information-sharing frameworks with large compute investors and thoroughly evaluate the risks posed by capability proliferation. Additionally, leaders can invest in and provide defensive solutions before offensive capabilities proliferate.
Governments should respond early to offense-dominant capabilities. In the future, AI models of a given performance could develop heavily offense-dominant capabilities (i.e., capabilities it is inherently difficult to defend against) or become inherently uncontrollable. Governments should closely monitor the emergence of such capabilities and preemptively develop mechanisms — including mechanisms for more tightly governing access to compute — that could substantially delay their proliferation if necessary.
Summary
Compute efficiency describes how efficiently investments in training compute can be converted into AI capabilities. It has been rising quickly over time due to improvements in both hardware price performance and algorithmic efficiency.
Rising compute efficiency will tend to cause new AI capabilities to diffuse widely after a relatively short period of time. However, since large compute investors also benefit from rising compute efficiency, they may be able to maintain their performance leads by pushing forward the frontier.
One governance implication is that large compute investors will remain an especially important target of oversight and regulation. At the same time, it will be necessary to prepare for — and likely, in some cases, work to delay — the widespread proliferation of dangerous capabilities.
Appendix
Competition between developers: complicating the picture
Our analysis — based on a simple model — has shown that increases in compute efficiency do not necessarily alter the leads of large compute investors. However, some additional considerations complicate the picture.
We will start out by noting some considerations that suggest that large compute investors companies may actually achieve even greater leads in the future. We will then move to considerations that point in the opposite direction.8
Leaders can further their performance advantages through scaling investments and proprietary algorithmic advancements. Large compute investors have historically scaled their compute investment significantly faster than others, widening the investment gap to smaller actors. Additionally, the proprietary development of algorithmic and hardware enhancements might further widen this divide, consolidating leaders’ competitive advantage.
In zero-sum competition, small relative performance advantages may grant outsized benefits. If AI models directly compete, the developer of the leading model may reap disproportionate benefits even if their absolute performance advantage is small. Such disproportionate rewards occur in games such as chess but likely also apply to AI models used in trading, law, or entertainment.
Winner-takes-all effects may allow leaders to entrench their lead despite losing their performance advantage. By initially developing the best-performing models, large compute investors may accrue a number of advantages unrelated to performance, such as network effects and economies of scale that allow them to maintain a competitive advantage even if they approach a performance ceiling.
Performance ceilings dampen the performance effect, reducing leaders’ advantage. Many AI applications have a ceiling on technical performance or real-world usefulness. For instance, handwritten digit classifiers have achieved above 99% accuracy since the early 2000s, so further progress is insignificant. As leaders approach the ceiling, performance only marginally increases with improved compute efficiency, allowing smaller actors to catch up.
Leaders can release their model parameters, allowing others to overcome compute investment barriers. Large compute investors can provide smaller actors access to their advanced models. While product integrations and structured access protocols allow for limited and fine-grained proliferation, releasing model parameters causes irreversible capability proliferation to a broad range of actors.
Ultimately — although increases in compute efficiency do not erode competitive advantages in any straightforward way — it is far from clear exactly how we should expect competition between developers to evolve.





















.jpg)










.jpg)

