In essence, RAGTruth is a large-scale corpus of naturally generated hallucinations, featuring detailed word-level annotations specifically designed for retrieval-augmented generation (RAG) scenarios.
Introduction
RAGTruth is a good illustration of how a hand-crafted dataset can be created and used to train an LLM for superior performance in identifying hallucinations by fine-tuning LLM with the RagTruth dataset.
This study again illustrates the growing trend of data design…Data design can be described as a process of designing and structuring data in such a way, not to augment the knowledge intensive nature of the model.
But rather to imbue the model with a specific and customised behaviour. In this case this behaviour is to optimise the model for a RAG implementation. There are other scenarios where the same is done to enhance the reasoning capabilities of a model, and so forth.
This study again underscores the importance of a data centric approach, where data discovery, data design and data development are central to the AI implementation.
The key is to have a highly flexible and intuitive data discovery and design UI. Where annotators are enabled and augmented via AI to improve speed and accuracy.
Four Categories Of Hallucination
The study is premised on four categories of hallucination…
Evident Conflict
Evident Conflict is described when generative content presents direct contraction or opposition to the provided information. These conflicts are easily verifiable without extensive context, often involving clear factual errors, misspelled names, incorrect numbers, etc.
Subtle Conflict
Subtle Conflict is described as when generative content presents a departure or divergence from the provided information, altering the intended contextual meaning.
These conflicts often involve substitution of terms that carry different implications or severity, requiring a deeper understanding of their contextual applications.
Evident Introduction Of Baseless Information
When generated content includes information not substantiated in the provided information. It involves the creation of hypothetical, fabricated, or hallucinatory details lacking evidence or support.
Subtle Introduction Of Baseless Information
When generated content extends beyond the provided information by incorporating inferred details, insights, or sentiments. This additional information lacks verifiability and might include subjective assumptions or commonly observed norms rather than explicit facts.
One key challenge is the lack of high-quality, large-scale datasets specifically designed for hallucination detection.
Data Gathering Pipeline
The image below shows the data gathering pipeline. The first of two steps is the response generation portion. Responses are generated with multiple LLMs using natural prompts.
Step two is where human annotation is made use of; the human labeller annotates hallucinated spans in the LLM responses.

The occasional generation of outputs that appear plausible but are factually incorrect significantly undermine the reliability of LLMs in real-world scenarios.
Three Most Used RAG Tasks
When tasks and data sources were selected, three most used RAG tasks were identified. Those were:
- Question Answering,
- Data-to-Text Writing, &
- News Summarisation.
To simplify the annotation process, the researchers selected only questions related to daily life and retained only three retrieved passages for each question. They then prompted the LLMs to generate answers based solely on these retrieved passages.
For the data-to-text writing task, the researchers prompted LLMs to generate an objective overview for a randomly sampled business in the restaurant and nightlife categories from the Yelp Open Dataset (Yelp, 2021).
In this dataset, information about a business is represented using structured data. To streamline the annotation process, the study focused on the following business information fields: BusinessParking, Restaurant Reservations, OutdoorSeating, WiFi, RestaurantsTakeOut, RestaurantsGoodForGroups, Music, and Ambience.
Additionally, to enrich the context information, they included up to three business-related user reviews. In the prompt, this information is represented in JSON format.
Human Annotation
Identifying AI-generated hallucinations is a challenging task that demands strong critical thinking skills to understand the logical flow of various texts and meticulous attention to detail to spot subtle inaccuracies and inconsistencies.
Additionally, a certain level of media literacy and knowledge of current affairs is crucial for understanding subjects discussed in news-related sample data.
Therefore, the researchers selected annotators who are proficient in English and possess a bachelor’s degree in English, Communications, or relevant fields to ensure the accuracy and reliability of the annotation results. The annotators were invited to perform annotation tasks using Label Studio.
Each labelling task was presented on one page and included the components:
- The context provided to the LLM
- Set of six responses generated by different AI models.
The image below shows the annotation interface, notice the business info on the left, the model answers in the middle, etc.
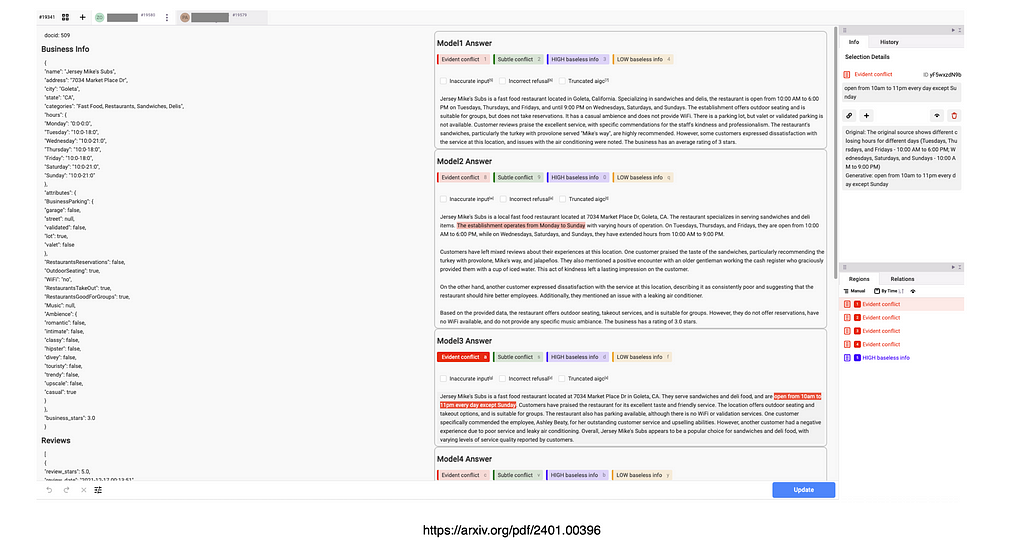
Their task was to annotate specific spans of the generated text that contained hallucinated information and categorize them into four types.
To ensure the quality of the annotations, each response was independently labeled by two annotators.
The consistency rate between the two annotators was 91.8% at the response level and 78.8% at the span level. In cases where there was a significant difference between the two annotations, a third review was conducted.
Finally
In essence RAGTruth is a large-scale corpus of naturally generated hallucinations, featuring detailed word-level annotations tailored for retrieval-augmented generation (RAG) scenarios.
This work also analysed the interplay between hallucinations and various factors, such as:
- Task types,
- Models being used, &
- Contextual settings.
Benchmarks of several hallucination detection approaches were created using this new corpus.
The Study demonstrates how a fine-tuned Llama with RAGTruth leads to competitive performance.
This suggests that using a high-quality dataset like RAGTruth can enable the development of specialised hallucination detection models that outperform prompt-based methods utilising general models such as GPT-4.
The findings also revealed that identifying hallucinations in RAG contexts, particularly at the span level, remains a formidable challenge, with current methods still falling short of reliable detection.
Meticulous manual annotations were performed on both an individual case and word levels.
⭐️ Follow me on LinkedIn for updates on Large Language Models ⭐️

I’m currently the Chief Evangelist @ Kore AI. I explore & write about all things at the intersection of AI & language; ranging from LLMs, Chatbots, Voicebots, Development Frameworks, Data-Centric latent spaces & more.